「Kaggle Advent Calendar 2022」の 7 日目の記事を担当します。 本記事では、今年参加した国際ワークショップでの機械学習コンペ「SemEval 2022 Task 8: Multilingual News Article Similarity」の概要とチームでの取り組みを紹介します。
SemEval とは
「SemEval (Semantic Evaluation)」は、計算意味解析システムの評価に焦点を当てている自然言語処理の国際ワークショップです。 前身を含めると 20 年以上の歴史があり、今年は「SemEval-2022 (The 16th International Workshop on Semantic Evaluation)」として開催されました。 12 個のコンペが設定された中で、私は特に関心が高かった「Task 8: Multilingual News Article Similarity」に参加しました。
Task 8: Multilingual News Article Similarity
名前の通り、多言語ニュースの類似度を判定するコンペでした。 記事のスタイル・政治的立場・媒体などではなく、ニュースの話題(地理的位置・時間・対象など)がどの程度一致しているかを軸にラベルが付けられています。
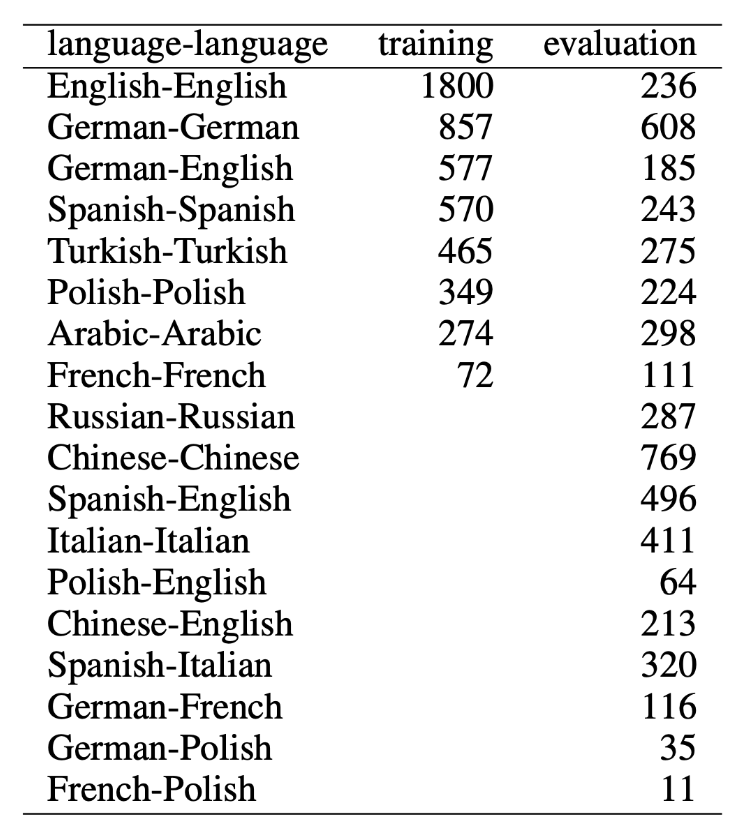
具体的には、2 つのニュース記事の見出し・本文などが与えられ、1-4 の範囲で一致度合いを予測します。 学習用(training)には 8 つの同一言語の組み合わせが与えられた一方で、評価用(evaluation)には異なる言語同士を含む組み合わせを扱う点が特徴的でした。
取り組み紹介
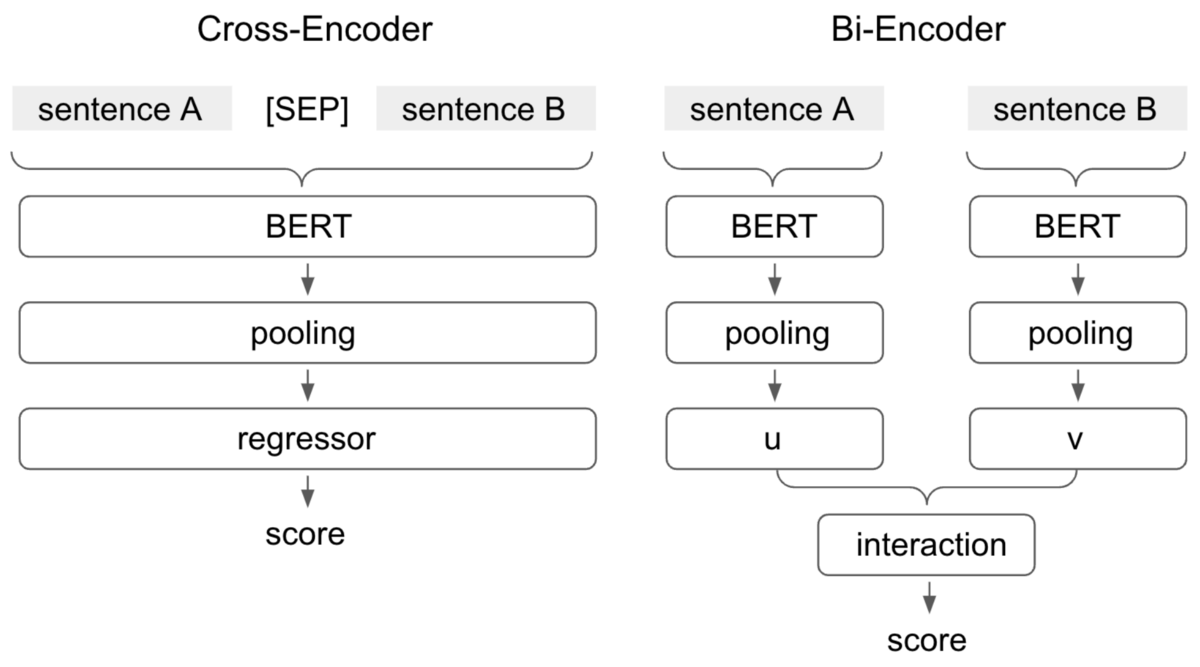
文や文書の組み合わせを扱うタスクでは、主に下図に示す 2 つのアプローチがあります。 Cross-Encoder は 2 つのテキストを 1 つのエンコーダーに入力する方法で、Bi-Encoder はそれぞれの入力を独立してエンコードする方法です。 今回チームでの実験では後者が良い結果につながり、最終的に 12 位という結果になりました。 取り組んだ内容は、論文の体裁にまとめて発表しました。 論文やソースコード、発表で用いた資料は、記事末尾にリンク集としてまとめています。
論文では具体的に、以下の 5 つの疑問に対する実験結果を報告しました。 1 点目については、既に説明した通り今回の実験では Bi-Encoder がうまく機能しました。 残りの点について、要点を掻い摘んで紹介します。
- Cross-Encoder と Bi-Encoder の違い?
- どの事前学習モデルが有効か?
- どのようなプーリング方法が適切か?
- 他言語を英語に翻訳するのは有効か?
- データ分割や最大長の影響はあるのか?
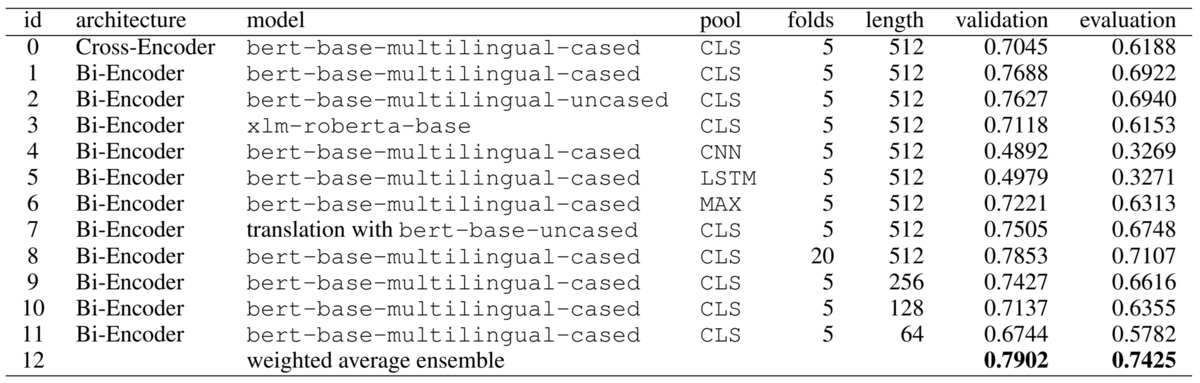
2 点目の事前学習モデルについては、自然言語処理ライブラリ「Transformers」で利用可能な多言語モデルから以下の 3 つを比較しました。いずれもある程度の性能が確認できています(実験 id:1-3)。
bert-base-multilingual-uncasedbert-base-multilingual-casedxlm-roberta-base
3 点目のプーリング手法については、以下の 4 つを比較しました。 今回の実験結果では、CLS が顕著に良い結果となりました(実験 id:1, 4-6)。
- CLS:最後の 4 層の CLS トークンの表現を連結
- CNN:畳み込みニューラルネットワーク(CNN)を利用して文ベクトルを抽出
- LSTM:長・短期記憶(LSTM)を用いて文ベクトルを抽出
- MAX:max-pooling を用いて文ベクトルを抽出
4 点目は、英語以外の言語を機械翻訳で英語に変換する方法を検証しました。 多言語に比べ、英語の方がより大規模で事前学習されたモデルが公開されており、高い性能に繋がる可能性があります。 ただし今回の実験結果では、性能の向上は確認できませんでした(実験 id:1, 7)。
最後の 5 点目は、データ分割や最大長の影響です。 交差検証の分割数を大きくすることで性能の向上(実験 id:1, 8)、最大長を小さくすることで性能の劣化(実験 id:1, 9-11)が観測されました。
最終的には、これらの探索の結果を踏まえて作成したモデルの出力を重み付き平均しました。 重み付き平均で、最も良い結果が得られています(実験 id:12)。
終わりに
本記事では、今年参加した SemEval 2022 の Task 8: Multilingual News Article Similarity の概要とチームでの取り組みを紹介しました。 機械学習コンペは、Kaggle のようなプラットフォーム以外に、SemEval のような国際学会・ワークショップでも開催されています。 選択肢の一つとして、ぜひ参加を検討してみてください。