「一発ジャンケン」の確率シミュレーション
Yahoo!ニュースを眺めていて見かけた「一発ジャンケン」が、プログラミングの教材として良さげだったので、実際に簡単なプログラムを組んでみました。ルールは以下の通りです(記事からの抜粋)。
まず、1~5を指で出す。数字が大きい人が勝ちなので5が一番強いが、他の人と同じ数字を出した人は負けとなる。5は強いが被りやすいという難点がある。ただ、残りが5と1なら革命で1が勝ちとなる。
import collections import random def determine_winner(choices): agg = collections.Counter(choices) only_one_choice = [i for i in agg.keys() if agg[i] == 1] if not only_one_choice: return 999, 999 elif set(only_one_choice) == set([1, 5]): return choices.index(1), 1 else: return choices.index(max(only_one_choice)), max(only_one_choice) if __name__ == "__main__": LARGE_NUMBER = 100000 N = 30 store = [] win_choice = [] for n in range(5, N): results = [ determine_winner([random.randint(1, 5) for _ in range(n)]) for _ in range(LARGE_NUMBER) ] store.append( collections.Counter([result[0] for result in results])[999] / LARGE_NUMBER ) win_choice.append(collections.Counter([result[1] for result in results]))
参加者数ごとの引き分けが発生する確率は以下の通りです。
import pandas as pd df = pd.DataFrame({ "The number of participants": range(5, N), "Draw probability": store, }) df.index = df["The number of participants"] df["Draw probability"].plot(xlabel="The number of participants", ylabel="Draw probability")
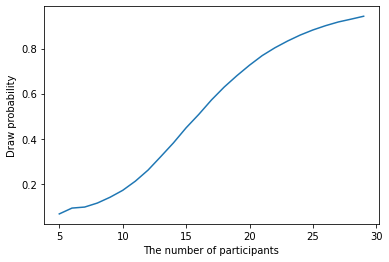
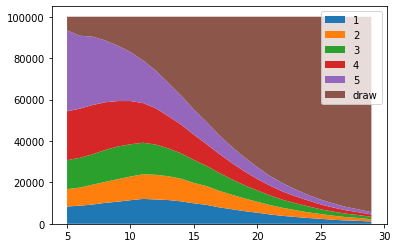
参加者数ごとの勝者となる手は以下の通りです。
import matplotlib.pyplot as plt v1 = [wc[1] for wc in win_choice] v2 = [wc[2] for wc in win_choice] v3 = [wc[3] for wc in win_choice] v4 = [wc[4] for wc in win_choice] v5 = [wc[5] for wc in win_choice] v999 = [wc[999] for wc in win_choice] labels = ["1", "2", "3", "4", "5", "draw"] fig, ax = plt.subplots() ax.stackplot(range(5, N), v1, v2, v3, v4, v5, v999, labels=labels) ax.legend(loc='upper right') plt.show()
機械学習を用いたサービス開発者として最近読んだ3冊
機械学習を用いたサービス開発者として、最近読んだ3冊の簡単な紹介です。 ここ2年ほどは、自らプロジェクトを設計して推進する立場も多くなってきました。 いずれも手元に置いておいて、しばらくして読み返すとまた違った気づきがあるような書籍だと思います。
『よくわかるパーソナルデータの教科書』(オーム社)
企業でのパーソナルデータの利活用について、法律・倫理・技術など分野横断で解説している書籍です。 平易な文章で具体例多めに書かれていて、非技術者でも取っ付きやすいと思います。
機械学習を活用する上で、入力となるデータや出力されたスコアの扱い方には細心の注意を払う必要があります。 「個人情報」や「パーソナルデータ」とは何か、情報技術分野との用語の使い方の違い、意識すべき観点など、頭の中を整理しておく上で役立つ情報がまとめられていると感じました。 改めて気を引き締め直す良い契機となりました。
『機械学習工学 (機械学習プロフェッショナルシリーズ)』(講談社)
機械学習を用いたソフトウェアの開発・テスト・運用の方法論について、体系的な整理を試みている書籍です。 機械学習が徐々に市民権を経て日常的に使われている中で、高い予測性能の実現に限らない広範な話題を扱っています。
目次を参考に興味のあるところだけ目を通し、必要に応じて参考文献を深掘りするような読み方ができそうです。 個人的には、第8章「機械学習と知財・契約」を特に重点的に読み込みました。
なお本書は、講談社からご恵贈いただきました。
『デジタル空間とどう向き合うか 情報的健康の実現をめざして』(日本経済新聞出版)
「フェイクニュース」「フィルターバブル」「エコーチェンバー」といったインターネットの登場で発生した新たな問題を取り上げ、解決に向けた方向性を議論している書籍です。 情報の受け手としてだけでなく、発信者・プラットフォーム運営者・政府などさまざまな立場で熟慮すべき視点を整理し議論しています。
著者はSNSや炎上の定量分析で有名な計算社会科学者の鳥海不二夫教授と、情報社会における人権や自由の問題を考察してきた法学者の山本龍彦教授です。 特に普段なかなか接する機会が多くない憲法学の視点からのメディアの役割の議論もあって、大いに勉強になりました。
【書籍メモ】『Pythonによる金融テキストマイニング』(朝倉書店)
『Pythonによる金融テキストマイニング』(朝倉書店)を読みました。180 ページ弱で金融関連文書を題材にした話題がまとまっていて、この領域に飛び込む初学者向けに紹介しやすい書籍だと感じました。
章立てを以下に示します。第 1 章で全体像を示した後、第 2 、 3 章で開発環境構築と MeCab などのツール・ライブラリを紹介します。第 4 章から第 7 章は、応用事例です。最後に第 8 章で、書籍内で扱えなかった話題や将来展望を解説しています。
- 金融テイストマイニングの概要
- 金融データ解析・機械学習の環境構築
- テキストマイニングツールの使い方
- 多変量解析を用いた日銀レポート解析と債券市場予測
- 深層学習を用いた価格予想
- ブートストラップ法を用いた業績要因抽出法
- 決算短信テキストからの因果関係の抽出
- 金融テキストマイニング応用の課題を将来
まず、第 4 章から第 7 章の応用事例のバランスが良いなと感じました。第 4 章は、伝統的な手法として形態素解析・頻度計算・主成分分析などを扱いつつ、後半は次章の金融時系列予測への導入にもなっています。近年一般的になっている深層学習の手法については、第 5 章で多層パーセプトロン・回帰型ニューラルネットワーク・畳み込みニューラルネットワーク、第 7 章では BERT を取り上げています。金融テキストマイニングというと金融時系列予測を想像しがちですが、第 6 章で業績要因、第 7 章で因果関係の抽出なども応用事例として紹介しています。
冒頭の繰り返しになりますが、金融関連文書を題材にした話題がまとまっていて初学者向けに紹介しやすい書籍だと感じました。自然言語処理や機械学習にある程度習熟している読者にとっては、第 1 章後半・第 2 章・第 3 章・第 5 章あたりは既知の部分も多く、サクサク読み進められると思います。個人的には第 8 章の現状と将来課題の整理が非常に勉強になりました。技術的課題の観点では、人工市場シミュレーションやマルチタスク学習などの発展的な話題にも言及しています。

国際会議「ACL2022」の "News" を含む論文の一言メモ
自然言語処理の最重要国際会議の一つ「ACL2022」の Proceedings にて "News" をタイトルに含む論文の一言メモです。要約・フェイクニュース検出・推薦の話題が多かった印象です。
Long Papers
- https://aclanthology.org/2022.acl-long.97/
- https://aclanthology.org/2022.acl-long.222/
- 読者がニュースの見出しにどのように反応するかを予測
- https://aclanthology.org/2022.acl-long.311/
- フェイクニュース検出には、個別の記事を見るだけではなく、最近の主流メディアの意見と人々の関心を考慮することが大切だと主張
- https://aclanthology.org/2022.acl-long.437/
- 株式リターンの予測に会社間の関係やニュースの情報などを利用
- https://aclanthology.org/2022.acl-long.446/
- 更新された記事を要約する際に、更新の前後の見出しを考慮するモデルを提案
- https://aclanthology.org/2022.acl-long.449/
Findings
- https://aclanthology.org/2022.findings-acl.29/
- ニュース推薦ではユーザの埋め込み表現を獲得するが、実際のユーザの好みは単一ではないので、複数のベクトルを使ってモデル化
- https://aclanthology.org/2022.findings-acl.42/
- ニュースの特定のトピックに着目した複数の要約パターンをまとめたデータセットを構築
- https://aclanthology.org/2022.findings-acl.46/
- https://aclanthology.org/2022.findings-acl.51/
- 複数記事を要約する際に、重要度に基づいて並び替えた後に文書を結合し入力とする方法で SoTA を達成
- https://aclanthology.org/2022.findings-acl.178/
- 2つの注意機構を搭載した説明力のあるアーキテクチャの提案
- https://aclanthology.org/2022.findings-acl.209/
- ニュース推薦タスクに記事本文以外の情報を使う際、特徴として結合するよりもマルチタスク学習にする方が良いと主張
- https://aclanthology.org/2022.findings-acl.274/
- 推薦で欠かせない候補列挙とリランキングを同一のモデルで処理
Workshops
- https://aclanthology.org/2022.acl-srw.17/
- https://aclanthology.org/2022.constraint-1.10/
- CLIP を用いてテキストとサムネイル画像の関係性を分析することで、フェイクニュース検出
- https://aclanthology.org/2022.fever-1.4/
- 多くのフェイクニュース検出モデルは表向きは本文の主張と証拠の関係性を分析しているが、実は主張を除去しても予測できてしまう(本質的な推論ができていないのでは?)
- https://aclanthology.org/2022.in2writing-1.10/
- ニュースで扱っている話題について、過去の関連記事を抽出
- https://aclanthology.org/2022.nlppower-1.5/
- 大規模な要約コーパス内に存在する不適切なサンプルのパターンを検知し、それらを除外することで要約モデルの性能向上を確認
- https://aclanthology.org/2022.wassa-1.20/
- ニュース記事に対する共感、感情、パーソナリティを予測する shared task の結果
【書籍メモ】『推薦システム実践入門――仕事で使える導入ガイド』(オライリー・ジャパン)
著者の松村優也さんのご厚意でお送りいただいた『推薦システム実践入門――仕事で使える導入ガイド』(オライリー・ジャパン)を読みました。帯にある「推薦システムを導入するときにまず手に取ってほしい」という謳い文句が言い得ている書籍だと感じました。

書籍の概要と所感
企業で推薦システムの構築に携わった経験がある著者らによる、推薦システム導入の手引きとなる一冊です。推薦システムの全体像を「インプット(データの入力)」「プロセス(推薦の計算)」「アウトプット(推薦の提示)」の3要素に分けて定義し、個別の章でUI/UX・アルゴリズム・評価などの観点を紐解いていきます。
推薦システムを考える際、どうしても注目を集めがちなのがプロセスの部分です。本書では第4・5章でこのプロセスの部分を具体的な実装と共に丁寧に解説しつつ、前段としてプロジェクト設計やUI/UXなど、企業で推薦システムを構築する上で必要不可欠な知識を言語化して整理している点が良い書籍だと感じました。第6章では推薦システムのデザインパターン、第7章では評価、第8章ではバイアスなどの発展的な話題も扱っています。書籍全体を通じて、推薦システムを取り巻く話題を広く押さえている印象です。
私自身の考えとして、企業の中で推薦システムを構築・運用していく上で大事なのは、実現可能な選択肢の全体像を把握しながら個別のビジネス要件に応じた在り方を議論していくことだと思っています。たとえば本書の分類に倣って例示すると、以下のような議題があります。
- インプット:どのようなユーザの属性情報や行動履歴の情報を利用できるのか、利用して良いのか。行動履歴の情報は明示的か暗黙的か。そこに偏りはないのか。
- プロセス:どの程度高度なアルゴリズムが必要なのか。開発や運用のコストは成果に見合うのか。何を基準に性能を評価するのか。
- アウトプット:ユーザにいつ、どのように推薦結果を示すのか。目的はどこにあるのか。
推薦システムに明確な「正解」はなく、個別のビジネス要件に応じた設計が必要になるはずです。本書で扱っているような内容を前提として押さえていると、要件に応じた在り方を企業の関係者らで広く議論していく上で、物事が円滑に進みやすくなると思います。内容は私自身ある程度理解している部分も多かったですが、あとがきにある通り「新入社員だった頃に知りたかった内容」が詰め込まれている書籍だと感じました。
おわりに
本記事では『推薦システム実践入門――仕事で使える導入ガイド』(オライリー・ジャパン)の概要と所感を紹介しました。 改めまして、実務で培った推薦システムに関する知見を日本語の書籍という形で丁寧にまとめてくださった著者のお三方にお礼申し上げます。
補足:推薦に関する機械学習コンテスト
本書の主題とは外れますが、映画推薦を題材とした「Netflix Prize」などの機械学習コンテストの話題も登場します。12ページにわたる付録でも言及されている通り、機械学習コンテストでのデータセット公開を通じて、推薦技術に関する研究・開発が大きく促進されました。データセットの匿名性や過度のアンサンブルなどの懸念点も当然ありますが、機械学習コンテストの貢献が窺い知れる内容となっています。
ちなみに、書籍をお送りいただいた松村さんとは、一緒に推薦を題材とした機械学習コンテストに参加したご縁がありました。
Shotaro Ishihara, Shuhei Goda, Yuya Matsumura (2021). Weighted Averaging of Various LSTM Models for Next Destination Recommendation, In Proceedings of the Workshop on Web Tourism co-located with the 14th ACM International WSDM Conference (WSDM 2021), March 12, 2021, Jerusalem, Israel, pp. 46-49.
直近の3イベントの登壇情報(3月26日〜4月4日)
3月26日〜4月4日に、3つのイベントに登壇します。スポーツ分析、業務、Kaggleとそれぞれ異なる話題について話します。ご関心あれば、ぜひご参加ください。
スポーツアナリティクスジャパン2022
3月26日の「スポーツアナリティクスジャパン2022」に登壇します。スポーツとデータ分析を題材にしたイベント「Sports Analyst Meetup」の運営メンバーとして、理念やこれまでの取り組みを紹介します。その他の登壇者も豪華で楽しみです。
Machine Learning Casual Talks #13 (Online)
3月30日の「Machine Learning Casual Talks #13 (Online)」に登壇します。機械学習プロジェクトに関する「Human In The Loop」を題材にしたイベントです。「The 5th IEEE Workshop on Human-in-the-Loop Methods and Future of Work in BigData」に採択された論文について解説します。
ML Study #3「機械学習コンペ」
4月4日の「ML Study #3 機械学習コンペ」に登壇します。ニュースレター「Weekly Kaggle News」の発行など、さまざまな形でコンペ関連の取り組みをした経験から感じた近年の潮流についてお話する予定です。広く機械学習に関わっている方に向けて、機械学習コンペおよびKaggleの2022年4月時点での実情が垣間見える発表になればと考えています。
2021年をザッと振り返る
年末恒例の振り返り記事です。今年は4月に職場での部署異動があり、役割範囲も大きく変わりました。研究開発部署にて、案件を自分自身で創出・推進していくことに挑戦した一年でした。
論文
主著では査読付きの国際会議ワークショップ3報(WSDM 2021、SIGIR 2021、IEEE BigData 2021)、受賞1(人工知能学会全国大会優秀賞)でした。 Computation + Journalism Symposium 2021 や言語処理学会第27回年次大会ワークショップでも発表したほか、共著でも人工知能学会全国大会にも投稿しました。
コミュニティ活動
世界各国で出版・公開された書籍 "Approaching (Almost) Any Machine Learning Problem" の翻訳書として、マイナビ出版から8月に『Kaggle Grandmasterに学ぶ 機械学習 実践アプローチ』と題した書籍を出版しました。 2020年の『Kaggleスタートブック』(講談社)に引き続き、今年も商用出版を経験できました。 現在も共著で1冊を執筆中で、来年中の刊行を目指しています。
2019年末に始めた週次のニュースレターは、今年も休刊なく継続できました。 YouTubeチャンネルにも15の動画を投稿しました。
はてなブログは本記事を含めて30記事を公開しました。 論文や書籍の執筆に重きを置いた影響で、100記事以上を達成していた例年に比べると少ない数字になっています。 会社での技術ブログは7記事書きました。
運営に関わっているイベント「Sports Analyst Meetup」を、3回(第10〜12回)開催できました。 特に第11回では「ARCS IDEATHON」と題して、ラグビートップリーグ所属ラグビーチーム「NTTコミュニケーションズシャイニングアークス」と共同でアイディアソンも開催しました。
その他、以下のイベントに登壇する機会を頂きました。 PyCon JPに採択されたこと、母校の高校・大学で卒業生として登壇できたことが印象に残っています。 関係者の皆様に、改めてお礼申し上げます。
- Pythonによるアクセスログ解析入門, PyCon JP 2021, Oct 16th, 2021.
- Kaggleの魅力と取り組み方, Kaggle Masterが語る【9/29ワークショップ】初心者のためのKaggle入門, Sep 29th, 2021.
- 高校生のためのオープンキャンパス 2021年度『東大卒業生に聞いてみようー18歳のハローワーク』, July 11th, 2021.
- 東海高校OBが語る!マスコミにおけるデータサイエンティストの仕事, 第39回サタデープログラム, June 26th, 2021.
コンペ
Kaggleでは、チーム参加した自然言語処理コンペ「CommonLit Readability Prize」で25位の銀メダルでした。 Notebooksカテゴリでは、Masterの称号を獲得しました。 「Kaggle Days Championship」のニューデリー予選ではチームで3位に入り、来年秋にスペイン・バルセロナで開催予定の本戦進出が決まりました。
その他のプラットフォームでは、以下のような成績でした。
- Nishika 判例の個人情報の自動マスキング 7th (Solo), 2021.
- NLP若手の会 (YANS) 第16回シンポジウム ハッカソン, 2nd (Team), 2021.
- SIGIR eCom'21 Data Challenge Purchase Intent Prediction, 3nd (Team), 2021.
- Solafune: 夜間光データから土地価格を予測 6th (Solo), 2021.
- 言語処理学会第27回年次大会(NLP2021)ワークショップ2 AI王 〜クイズAI日本一決定戦〜 ライブコンペティション 5th (Team), 2021.
- ACM WSDM Workshop on Web Tourism (WSDM Webtour'21), 6th (Team), 2021.
おわりに
今年は試行錯誤を重ねながら、自分の幅を広げる活動に取り組んだ一年だったと感じます。 年末にかけて原稿・研究などさまざま仕込んでいる段階なので、来年以降にお披露目できるのが楽しみです。