Kaggle Notebooks Master になった
2018 年の GW に Kaggle を本格的に始めて丸 3 年、Notebooks カテゴリで Master の称号を獲得しました。

2019 年 4 月に終了したコンペでチームメイトにも恵まれ金メダルを獲得できた後、入門記事や入門書など、主に日本人参加者の Kaggle に対する障壁を下げて裾野を広げたいと考えていました。副次的な報酬として、Kaggle 上で一つの節目となる称号が得られたのは非常に嬉しいです。
Competitions 部門で Master になった際、以下のような投稿をしていました。齢を重ねつつある中、3 年以上も打ち込める趣味に出合えて良かったなと改めて感じています。
2018年のGWにKaggleを始めて約1年、Kaggle Masterになりました🎉 twitterやkaggler-ja slackなどで多くの方とやり取りさせていただき、ここまで成長できたと思います。コミュニティに貢献できるよう、今後も精進してきたいです💪 pic.twitter.com/acJ4ZgyHuo
— u++ (@upura0) June 4, 2019
次なる Master の目標は Discussions 部門になりますが、狙いに行くものというより、コンペに真面目に参戦する中で自然と積み上がっていくものだと捉えています。なかなか Kaggle コンペで金メダルを取れていませんが、機を見て挑戦していきたいところです。

中国語繁体字版『PythonではじめるKaggleスタートブック』
Google Code Jam 2021 Qualification Round 参加録
「Google Code Jam 2021」の Qualification Round に参加しました。「Code Jam」は、Googleが主催する世界的なコーディングコンテストで、Qualification Round は最初の予選です。今年は日本時間の3月26日22時〜28日午前4時にわたり開催され、出題5問から合計30点以上を獲得することで次のラウンドに進出できます。
競プロに挑戦するのは久々でしたが、今回無事に31点を獲得できました。本記事では、解法をまとめます。
 Code Jam - Google’s Coding Competitions
Code Jam - Google’s Coding Competitions
Reversort (7点)
1問目は、データ構造とアルゴリズムで頻出の「ソート」が題材でした。制約の数字も大きくないので、問題文の指示に従って愚直に実装すれば通ります。
T = int(input()) case_id = 0 for test_case in range(T): cost = 0 case_id += 1 N = int(input()) L = list(map(int, input().split())) for i in range(N - 1): min_j = L[i] min_j_idx = i for j in range(i + 1, N): if min_j > L[j]: min_j = min(min_j, L[j]) min_j_idx = j cost += (min_j_idx - i + 1) L[i: min_j_idx + 1] = L[i: min_j_idx + 1][::-1] print(f'Case #{case_id}:', cost)
Moons and Umbrellas (5 + 11 + 1点)
2問目は、文字列に関する話題でした。問題文を読んで、?をどう処理するかを考えるのが肝になります。?が何個連続するのか、?が両端にあるのかなどのパターンを挙げていきながら考えていきました。コストX, Yが0以上の場合には、?が何個連続しようがCもしくはJを連続させることで、部分文字列のコストがXかYに帰着します。
Pythonの場合は文字列の正規表現を用いて次のように実装できます。
import re T = int(input()) S = [list(input().split()) for i in range(T)] case_id = 0 for test_case in range(T): x, y, s = S[case_id] x = int(x) y = int(y) cost = 0 cost += (len(re.findall(r'C\?*J', s)) * x) cost += (len(re.findall(r'J\?*C', s)) * y) case_id += 1 print(f'Case #{case_id}:', cost)
Reversort Engineering (7 + 11点)
第1問の応用問題です。問題文の制約を見ると、7点のテストケースは総当たりで通せそうです。この時点で24点を積み上げていたため、まずは確実に7点を取りに行きました。
import itertools def calc_cost(L): cost = 0 for i in range(N - 1): min_j = L[i] min_j_idx = i for j in range(i + 1, N): if min_j > L[j]: min_j = min(min_j, L[j]) min_j_idx = j cost += (min_j_idx - i + 1) L[i: min_j_idx + 1] = L[i: min_j_idx + 1][::-1] return cost def check_list(N, C): for candidate in list(itertools.permutations([i + 1 for i in range(N)])): candidate_list = list(candidate) cost = calc_cost(candidate_list) if cost == C: ans = [str(c) for c in list(candidate)] return ' '.join(ans) return 'IMPOSSIBLE' T = int(input()) case_id = 0 for test_case in range(T): case_id += 1 N, C = list(map(int, input().split())) ans = check_list(N, C) print(f'Case #{case_id}:', ans)
おわりに
本記事では「Google Code Jam 2021」の Qualification Round の解法をまとめました。
【YouTube更新】大学入学共通テスト「情報」(プログラミング)のサンプル問題を解いてみた
言語処理学会第27回年次大会ワークショップ「AI王 〜クイズAI日本一決定戦〜」参加録
言語処理学会第 27 回年次大会のワークショップとして開催されていた「AI王 〜クイズAI日本一決定戦〜」*1に参加しました。Kaggle などで親交のある atfujita さんとのチームで、最終結果は 5 位でした。
コンペ概要
日本語の 20 択のクイズ問題に回答する課題でした。データセットとして質問文・選択肢・回答のための Wikipedia データが与えられました。
暫定の評価用データセットを用いた順位表は、2020年4月から公開されていました*2。その順位表を通じて各自がモデルを改善しつつ、2021年3月19日に実施されたイベント内で新しい評価用データセットに対する性能を競うという形式でした。
チームとしての取り組み
チームとしての取り組みは、ワークショップ内でシステム報告として口頭発表しました。資料は下記の通り公開しています。基本的には運営が公開しているベンチマークコード*3を軸にしつつ、BERT の事前学習済モデルを含めた細かな拡張を重ねながら多様性を生み、最後にアンサンブルで性能を高めました。
他チームの取り組み
暫定の順位表で 1 位を獲得した方をはじめ、データの前処理に注力していたチームが多かった印象でした。事前学習済モデルによる取り組みが一般的な時代において、前処理の重要性を改めて実感する良い機会となりました。
私が知る限りの公開されている資料は、記事末尾にまとめました。
おわりに
日本語の質問応答という、題材としては馴染みがありつつも、モデル構築という観点では初めての領域に挑戦できました。コロナ禍の影響で当初の計画通りに行かない部分も多かったのではないかと推察しますが、データセットを公開しコンペを運営してくださった皆さんに感謝いたします。またチームを組んだ atfujita さんや、ワークショップ内で知見を共有してくださった参加者の皆さまにも、改めてお礼申し上げます。ベンチマークコードを読み解いたり(時に修正の PR を送ったり)、古典的な手法を再考したり、関連の論文を調査したりで、学びの深いコンペでした。
公開資料
公開されている資料をまとめました。
招待講演
コンペ解法
国際会議「ACM WSDM」のワークショップ「Booking.com Data Challenge」で6位に
国際会議「ACM WSDM」のワークショップとして開催されていた「Booking.com Data Challenge」*1で6位に入りました*2。Wantedly の hakubishin3 さんと Yuya Matsumura さん とのチームで、解法をまとめた論文は同ワークショップに採択・公開されました*3。同ワークショップは日本時間12日夜に開催され、主催者や上位チームがプレゼンテーションを実施します。

図は *2 より引用。
コンペ概要
世界最大規模の旅行代理店サイト「Booking.com」が主催で、たとえば「A->B->C」の旅程のユーザが、次にどこに行くか当てるという課題でした。このタスクが解けると、ユーザが旅行を予約した際に即座に「合わせて○○にも行ってみてはいかがですか?」といった推薦が実現できると説明されていました。
データセットとしては、以下の情報が与えられました。
- user_id: ユーザID
- check-in: ホテルのチェックイン日
- checkout: ホテルのチェックアウト日
- affiliate_id: ユーザのサイト訪問経路(直接か検索エンジンなど)
- device_class: デスクトップかモバイルか
- booker_country: ユーザの国(匿名)
- hotel_country: ホテルの国(匿名)
- city_id: 予測対象の都市(匿名)
- utrip_id: 旅程をまとめるID
Kaggle などのコンペと比べ、中間・最終にそれぞれ一度しかテスト用データセットへの予測値を提出できないのも特徴的でした。評価指標は「Precision@4」(4つの候補を挙げた上での正解率)でした。
チーム解法
最終的には4種類のLSTMモデルを作成し、予測値を重み付き平均しました。最初に主催者が公開している情報*4*5を基にベースラインとなるモデルを構築し、チームメイトと共に徐々に改善を重ねていきました。詳細は公開された論文*6やソースコード*7*8をご参照ください。

図は *6 より引用。
工夫した点をいくつか紹介しておきます。
まずは本来使えないはずの「予測対象の都市の滞在日数」という特徴量です。今回のコンペでは、実際に推薦を実施する時点では分からないはずの「予測対象のホテルのチェックアウト日」が与えられており、滞在した日数が計算できてしまいました。滞在日数は都市の特徴をよく表すことが想像でき、実際に性能の向上に貢献しました。

図は *6 より引用。
ニューラルネットワークの構造の工夫としては、都市と同時に国を当てるタスクも解く「マルチタスク・ラーニング」の枠組みも導入しました。

図は *6 より引用。
与えられたデータセットから、Word2Vecなどのグラフ関係の特徴量も作成しました。得られた都市のベクトル表現を2次元で可視化した結果を下図に示します。遠い目で見ると、世界地図に見えなくもない気もしました。

図は *6 より引用。
おわりに
本記事では、チーム参加して6位に入った「Booking.com Data Challenge」について紹介しました。旅行という身近で面白い題材に取り組みつつ、最終的には論文も書けて非常に有意義なコンペでした。一緒に取り組んだチームメイトに改めて感謝します。
*6:Shotaro Ishihara, Shuhei Goda and Yuya Matsumura: Weighted Averaging of Various LSTM Models for Next Destination Recommendation.
「GPT-3」周辺で調べたことをまとめる(2021年2月)
コンピュータサイエンス技術の一つに、自然言語処理(NLP)と呼ばれている領域があります。NLPは、コンピュータに人間の用いる言語(自然言語)を処理させる取り組み全般を指します。
ここ数年のNLPの傾向として、大規模テキストでの事前学習済みモデルの活用が挙げられます。代表的な例が、Googleが2018年10月に発表した「Bidirectional Encoder Representations from Transformers (BERT)」*1です。BERTは多数のNLPタスクで飛躍的な性能を示し、注目を集めました。BERTの登場後、大規模テキストを用いた巨大モデルを学習させていく流れが強まっています*2。
BERTの登場以前は、個別のタスクに対してモデルを訓練する取り組みが優勢でした。一方でBERTでは、事前に大量のテキストデータを用いて巨大なニューラルネットワークを学習させて汎用的なモデルを獲得し(事前学習)、その後に個別のタスクにモデルを適用していきます(ファインチューニング)。BERTの成果は、既に多くの領域で活用されています。Googleは2019年10月に自社の検索エンジンのアルゴリズムをBERTに基づく仕組みに刷新しました。同年12月には、日本語を含む72言語に拡張されました*3。
GPT-3の初期版の論文は、BERT登場前の2018年6月に公開されています*4。このモデルでは、BERTでも使われている「Transformer」と呼ばれる機構を12層用いて、言語モデルがファインチューニングを見据えた上での事前学習として有効であると示しました。言語モデルとは文の生成確率を定義したモデルで、近年はニューラルネットワークを用いて確率を推定するのが一般的です。本論文では「GPT」は「Generative Pre-Training」(生成的な事前学習)の略とされています。なお、GPTの研究に取り組んでいるのは、米電気自動車大手テスラCEOのイーロン・マスク氏らが共同設立したAI研究の非営利組織「OpenAI」です。
OpenAIは2019年2月、48層のTransformer機構を備えた「GPT-2」を発表しました*5。GPT-2は、ファインチューニングを実施せず、文章生成などのタスクに適用できる(ゼロショット)のが特徴です。
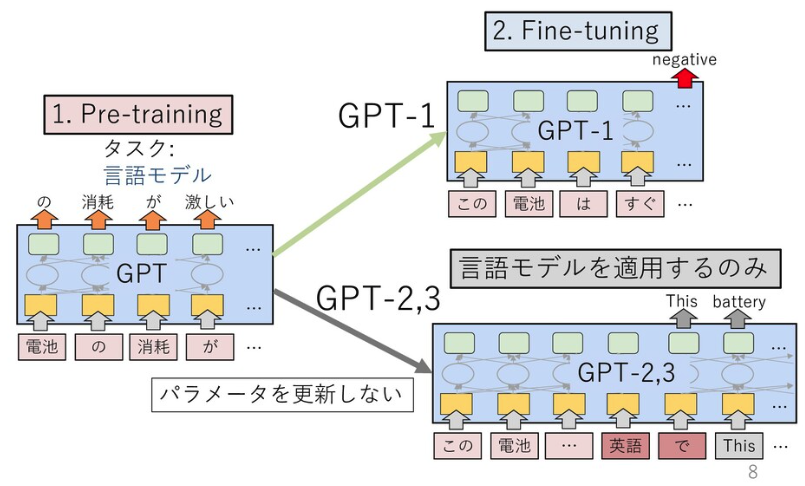 図は *6 より引用。
図は *6 より引用。
GPT-2は、人間も判別がつかないほどの高品質のフェイクニュースを生成できるとして、大きな話題を呼びました。発表時にはOpenAIが危険性を危惧し、論文公開を延期しモデルの公開も段階的に実施されました*7。
2020年5月に発表されたGPT-3は、GPT-2のパラメータ数を約116倍に拡張したモデルです*8。GPT-2ではゼロショットという枠組みを利用していましたが、GPT-3では少量の正答例を付与することで個別のタスクにモデルを適用します(Few-shot、フューショット)。具体的には、次のようにTask description(タスクの説明)、examples(回答例)、prompt(回答を促す文)を与えることで、回答を導出する枠組みです。ここで、GPT関連の論文で登場する「ゼロショット」「フューショット」という枠組みについては、その他一般で登場する同語と異なる概念になっている点には注意が必要です*9。
 図は [8] より引用。
図は [8] より引用。
OpenAIは2020年6月、GPT-3のAPIを公開しました。このAPIを駆使したデモを通じ、GPT-3の凄さが一挙に世間に広まりました*10*11。文章生成だけではなく、検索やLaTeXの数式・HTML・ソースコードの生成といったデモが公開されています。2020年8月には、米国の大学生がGPT-3で生成した偽のブログ記事で、ニュースサイト「Hacker News」のランキング1位を獲得したことも話題になりました*12。2020年10月には、MicrosoftがこのAPIの独占ライセンスを取得しています*13。
NLPの性能競争では、膨大なデータセットと巨大な計算資源が必要という潮流が強まっています。Transformer機構を用いた言語モデルの性能は、パラメータ数N・データセットサイズD・計算予算Cを変数とした冪乗則に従うという法則がOpenAIによって示されています*14。ウェブ上のデータセットは英語であることなどから、日本語に関する研究は英語圏に比べ遅れを取っていると言われています。日本でも一部の組織や開発者有志によって、日本語に関する言語モデルを学習・公開している事例はあります*15*16*17。2020年11月には、LINE株式会社がNAVERと共同で日本語に特化した超巨大言語モデルの開発についての取り組みを発表しました*18。
2021年1月、OpenAIは文章に忠実な画像を生成する「DALL·E」を発表しました*19。テキストと画像のペアのデータセットをGPT-3と同様の形式で学習したモデルです。GPT-3などで使われているTransformer機構は画像認識などNLP領域以外でも成果を発揮しつつあり、今後のさまざまな応用に期待が高まっています。DALL·Eと同時に発表された「CLIP」では、テキストを教師データとして利用した画像分類モデルが提案されました*20。CLIPは、GPT-2のゼロショットという枠組みに落とし込まれています。
*1:https://arxiv.org/abs/1810.04805
*2:https://speakerdeck.com/kyoun/survey-of-pretrained-language-models-f6319c84-a3bc-42ed-b7b9-05e2588b12c7
*3:https://www.blog.google/products/search/search-language-understanding-bert/
*4:https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
*5:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
*6:https://speakerdeck.com/tomohideshibata/gpt-3
*7:https://openai.com/blog/better-language-models/
*8:https://arxiv.org/abs/2005.14165
*9:https://zenn.dev/dhirooka/articles/34205e1b423a80
*10:https://deeplearning.hatenablog.com/entry/gpt3
*11:https://airtable.com/shrndwzEx01al2jHM/tblYMAiGeDLXe35jC
*12:https://www.technologyreview.com/2020/08/14/1006780/ai-gpt-3-fake-blog-reached-top-of-hacker-news/
*13:https://blogs.microsoft.com/blog/2020/09/22/microsoft-teams-up-with-openai-to-exclusively-license-gpt-3-language-model/
*14:https://deeplearning.hatenablog.com/entry/scaling_law
*15:https://github.com/tanreinama/gpt2-japanese
*16:https://cl.asahi.com/api_data/language_model.html
*17:https://tech.stockmark.co.jp/blog/gpt2_ja/
*18:https://linecorp.com/ja/pr/news/ja/2020/3508
*19:https://github.com/openai/DALL-E
*20:https://www.slideshare.net/DeepLearningJP2016/dllearning-transferable-visual-models-from-natural-language-supervision