コンピュータサイエンス技術の一つに、自然言語処理(NLP)と呼ばれている領域があります。NLPは、コンピュータに人間の用いる言語(自然言語)を処理させる取り組み全般を指します。
ここ数年のNLPの傾向として、大規模テキストでの事前学習済みモデルの活用が挙げられます。代表的な例が、Googleが2018年10月に発表した「Bidirectional Encoder Representations from Transformers (BERT)」*1です。BERTは多数のNLPタスクで飛躍的な性能を示し、注目を集めました。BERTの登場後、大規模テキストを用いた巨大モデルを学習させていく流れが強まっています*2。
BERTの登場以前は、個別のタスクに対してモデルを訓練する取り組みが優勢でした。一方でBERTでは、事前に大量のテキストデータを用いて巨大なニューラルネットワークを学習させて汎用的なモデルを獲得し(事前学習)、その後に個別のタスクにモデルを適用していきます(ファインチューニング)。BERTの成果は、既に多くの領域で活用されています。Googleは2019年10月に自社の検索エンジンのアルゴリズムをBERTに基づく仕組みに刷新しました。同年12月には、日本語を含む72言語に拡張されました*3。
GPT-3の初期版の論文は、BERT登場前の2018年6月に公開されています*4。このモデルでは、BERTでも使われている「Transformer」と呼ばれる機構を12層用いて、言語モデルがファインチューニングを見据えた上での事前学習として有効であると示しました。言語モデルとは文の生成確率を定義したモデルで、近年はニューラルネットワークを用いて確率を推定するのが一般的です。本論文では「GPT」は「Generative Pre-Training」(生成的な事前学習)の略とされています。なお、GPTの研究に取り組んでいるのは、米電気自動車大手テスラCEOのイーロン・マスク氏らが共同設立したAI研究の非営利組織「OpenAI」です。
OpenAIは2019年2月、48層のTransformer機構を備えた「GPT-2」を発表しました*5。GPT-2は、ファインチューニングを実施せず、文章生成などのタスクに適用できる(ゼロショット)のが特徴です。
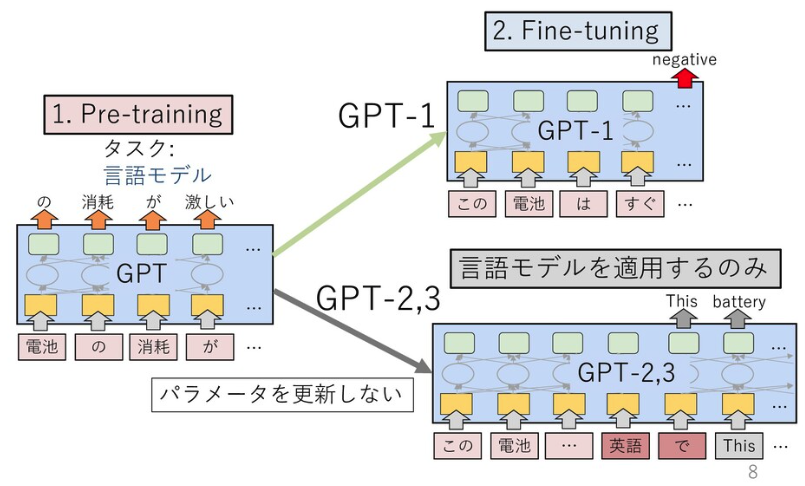 図は *6 より引用。
図は *6 より引用。
GPT-2は、人間も判別がつかないほどの高品質のフェイクニュースを生成できるとして、大きな話題を呼びました。発表時にはOpenAIが危険性を危惧し、論文公開を延期しモデルの公開も段階的に実施されました*7。
2020年5月に発表されたGPT-3は、GPT-2のパラメータ数を約116倍に拡張したモデルです*8。GPT-2ではゼロショットという枠組みを利用していましたが、GPT-3では少量の正答例を付与することで個別のタスクにモデルを適用します(Few-shot、フューショット)。具体的には、次のようにTask description(タスクの説明)、examples(回答例)、prompt(回答を促す文)を与えることで、回答を導出する枠組みです。ここで、GPT関連の論文で登場する「ゼロショット」「フューショット」という枠組みについては、その他一般で登場する同語と異なる概念になっている点には注意が必要です*9。
 図は [8] より引用。
図は [8] より引用。
OpenAIは2020年6月、GPT-3のAPIを公開しました。このAPIを駆使したデモを通じ、GPT-3の凄さが一挙に世間に広まりました*10*11。文章生成だけではなく、検索やLaTeXの数式・HTML・ソースコードの生成といったデモが公開されています。2020年8月には、米国の大学生がGPT-3で生成した偽のブログ記事で、ニュースサイト「Hacker News」のランキング1位を獲得したことも話題になりました*12。2020年10月には、MicrosoftがこのAPIの独占ライセンスを取得しています*13。
NLPの性能競争では、膨大なデータセットと巨大な計算資源が必要という潮流が強まっています。Transformer機構を用いた言語モデルの性能は、パラメータ数N・データセットサイズD・計算予算Cを変数とした冪乗則に従うという法則がOpenAIによって示されています*14。ウェブ上のデータセットは英語であることなどから、日本語に関する研究は英語圏に比べ遅れを取っていると言われています。日本でも一部の組織や開発者有志によって、日本語に関する言語モデルを学習・公開している事例はあります*15*16*17。2020年11月には、LINE株式会社がNAVERと共同で日本語に特化した超巨大言語モデルの開発についての取り組みを発表しました*18。
2021年1月、OpenAIは文章に忠実な画像を生成する「DALL·E」を発表しました*19。テキストと画像のペアのデータセットをGPT-3と同様の形式で学習したモデルです。GPT-3などで使われているTransformer機構は画像認識などNLP領域以外でも成果を発揮しつつあり、今後のさまざまな応用に期待が高まっています。DALL·Eと同時に発表された「CLIP」では、テキストを教師データとして利用した画像分類モデルが提案されました*20。CLIPは、GPT-2のゼロショットという枠組みに落とし込まれています。
*1:https://arxiv.org/abs/1810.04805
*2:https://speakerdeck.com/kyoun/survey-of-pretrained-language-models-f6319c84-a3bc-42ed-b7b9-05e2588b12c7
*3:https://www.blog.google/products/search/search-language-understanding-bert/
*4:https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
*5:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
*6:https://speakerdeck.com/tomohideshibata/gpt-3
*7:https://openai.com/blog/better-language-models/
*8:https://arxiv.org/abs/2005.14165
*9:https://zenn.dev/dhirooka/articles/34205e1b423a80
*10:https://deeplearning.hatenablog.com/entry/gpt3
*11:https://airtable.com/shrndwzEx01al2jHM/tblYMAiGeDLXe35jC
*12:https://www.technologyreview.com/2020/08/14/1006780/ai-gpt-3-fake-blog-reached-top-of-hacker-news/
*13:https://blogs.microsoft.com/blog/2020/09/22/microsoft-teams-up-with-openai-to-exclusively-license-gpt-3-language-model/
*14:https://deeplearning.hatenablog.com/entry/scaling_law
*15:https://github.com/tanreinama/gpt2-japanese
*16:https://cl.asahi.com/api_data/language_model.html
*17:https://tech.stockmark.co.jp/blog/gpt2_ja/
*18:https://linecorp.com/ja/pr/news/ja/2020/3508
*19:https://github.com/openai/DALL-E
*20:https://www.slideshare.net/DeepLearningJP2016/dllearning-transferable-visual-models-from-natural-language-supervision