TF-IDFを用いた「Kaggle流行語大賞2020」
Kaggle Advent Calendar の8日目の記事です。
2018年、2019年に引き続き、今年もTF-IDFを用いた「Kaggle流行語大賞」を算出します。具体的には、2020年に公開されたNotebookのタイトル情報から、頻繁に登場した単語をランキング形式でまとめました。
2018年*1と2019年*2は「探索的データ分析(Explanatory Data Analysis, EDA)」が1位となりました。
それでは今年の結果を見ていきましょう。
集計方法
概ね昨年と同様の方法を採用しました。一連の処理はKaggleのNotebook*3にて公開しています。
データセット
「Meta Kaggle」*4のデータセット「Kernels.csv」を利用しました。公開されているNotebookの公開日・URLなどの情報が格納されています。
NotebookのURLは、ユーザが付けたタイトルに基づいて決まります。下図のように「Simple lightGBM KFold」というタイトルの場合は「simple-lightgbm-kfold」です。
Notebookの絞り込み
一定の評価を受けたNotebookに絞り込むため、次の処理を実施して「Voteを1以上得たNotebook」に集計対象を限定します。
kernels = kernels.query('TotalVotes > 0')
年ごとに分割
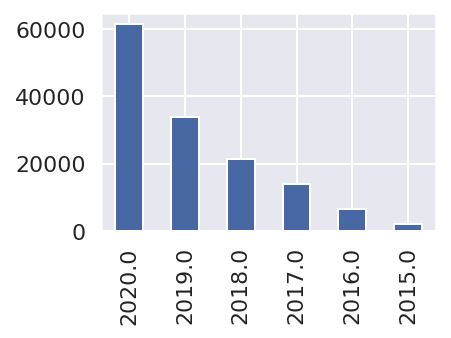
「公開年」別に集計すると、次のようになりました。公開されたNotebookは年々増加しています。
kernels['Date'] = pd.to_datetime(kernels['MadePublicDate']) kernels['Date'].dt.year.value_counts().plot.bar()
TF-IDFを計算
最後に、年を文書、タイトルを文の単位として捉えて「TF-IDF」を計算します。詳細は割愛しますが、多くの年で出現する語(一般的な語)は重要度が下がり、特定の年にしか出現しない単語の重要度は上がるような計算を施すことになります。あらかじめnltk.corpus内の英語のstopwordsを指定して、a, the, ofなどの一般的すぎる単語は取り除いています。
昨年までは筆者の判断でKaggle特有の一般的な単語やコンペのタイトル名に含まれる単語などを除外していましたが、今年は恣意性を排除するために特別な処理は止めました。
from nltk.corpus import stopwords from sklearn.feature_extraction.text import TfidfVectorizer stopWords = stopwords.words("english") vectorizer = TfidfVectorizer(stop_words=stopWords)
結果発表
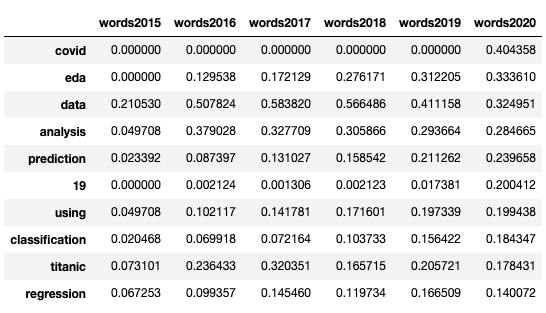
2020年のTF-IDFの値で降順にソートした上位10件を以下に示します。2020年の首位は、突如現れた「covid」でした。「COVID19 Global Forecasting (Week 1) 」コンペ*5や「OpenVaccine: COVID-19 mRNA Vaccine Degradation Prediction」コンペ*6など、COVID-19を題材にしたコンペが複数開催されたのが要因だと考えられます。6位の「19」も、COVID-19から起因するものでしょう。
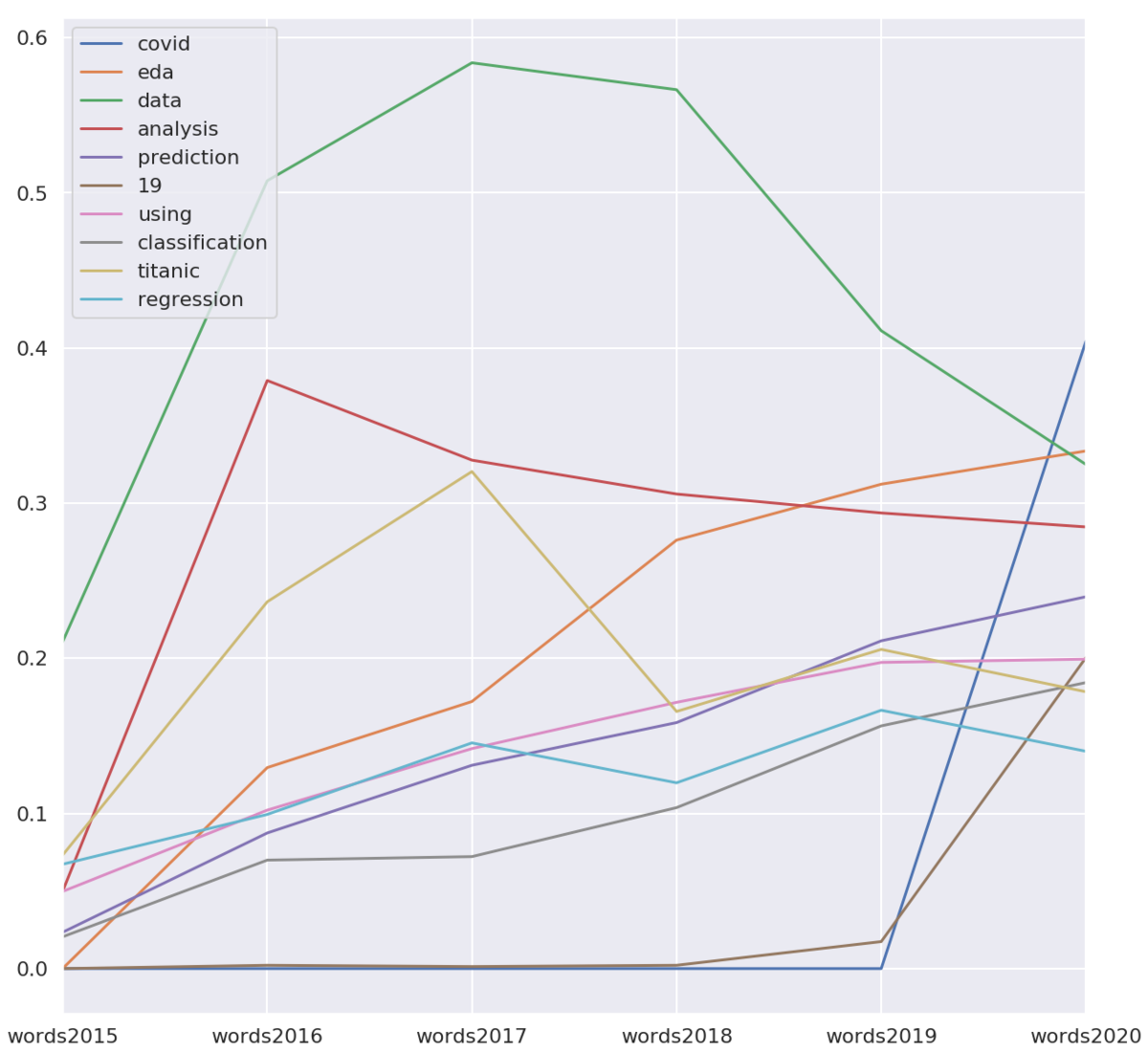
年次の推移は次の通りです。「covid」「19」が2020年に大きくスコアを伸ばしていると分かります。「data」「analysis」を除き2年連続で首位を守ってきた「eda」は、2位になりました。今年は「data」「analysis」を上回りましたが、それ以上にCOVID-19が流行していたという結果でした。
初学者向けコンペの「titanic」は、2015〜2017年に「data」「analysis」を除き1位になっていました。2018年以降は、徐々に順位を落としています。
おわりに
本記事では昨年に引き続き、TF-IDFを用いた「Kaggle流行語大賞」を算出しました。
今年1年も存分に楽しませてもらったKaggleに感謝しつつ、来年もKaggleを楽しんでいきたいです。