本記事について
- 「スポーツアナリティクス Advent Calendar 2020」*1の1日目の記事です。
- 12月13日開催の「Sports Analyst Meetup #9」*2で発表予定の内容をまとめました。
概要
- 2019年12月〜2020年9月に開催されていた「Basketball Behavior Challenge: BBC2020」*3の1位解法の紹介
- 時系列の座標データから「スクリーンプレイ」があったか否かを判定するコンペ
自己紹介
- 「Sports Analyst Meetup (spoana)」の運営メンバー
- 本業はメディア企業のデータサイエンティスト
- 本コンペは、spoana #7のLT発表で知った(アーカイブ)*4
- 共著に『PythonではじめるKaggleスタートブック』(講談社)*5
データの概要
バスケットボールの1プレイずつ切り取った座標データが提供されました。各プレイでは、同じチームの2プレイヤー scr と usr と相手チームのプレイヤー uDF、およびボール bal のx軸とy軸の値がフレーム単位で与えられています。
frame scr_x scr_y usr_x usr_y uDF_x uDF_y bal_x bal_y 0 2.89 4.74 5.49 1.5 2.78 5.22 6.98 12.7 1 2.88 4.7 5.52 1.51 2.8 5.2 7.08 12.52 2 2.87 4.67 5.54 1.53 2.82 5.19 7.13 12.35 3 2.86 4.65 5.56 1.54 2.84 5.17 7.08 12.37 ...
正例のデータはスクリーンプレイを含み、負例のデータは含みません。具体的にどのようなデータなのかは、コンペページの可視化が分かりやすいです。
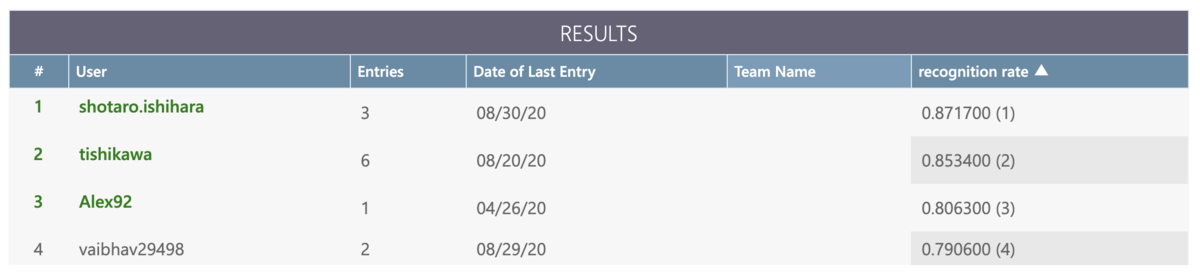
スコアの推移
次図は、私のスコアの推移です。最終的には、約0.87の正答率で未知のデータの結果を当てることができました。
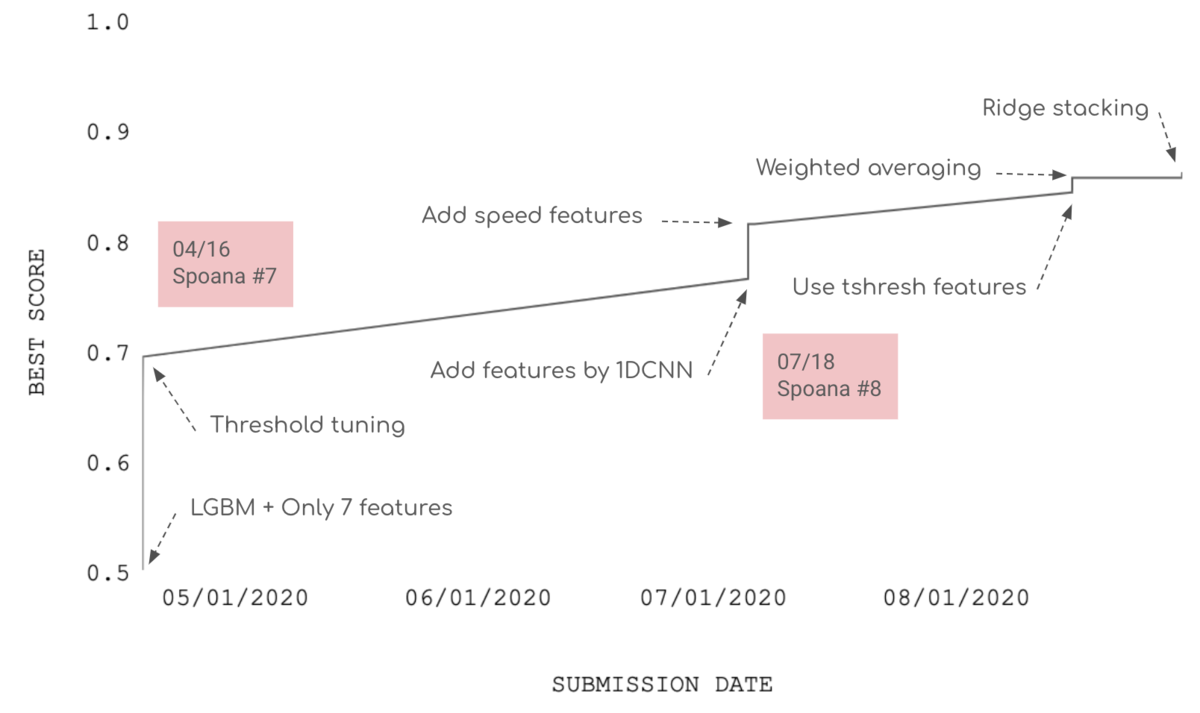
機械学習の教師あり学習
予測モデルの作成には、機械学習の教師あり学習と呼ばれる技術を利用しました。次図に示す通り、答えが分かっているデータから「特徴量」 X_train と正解 y_train のペアを作成し、未知のデータ X_test に対する予測を導く考え方です。
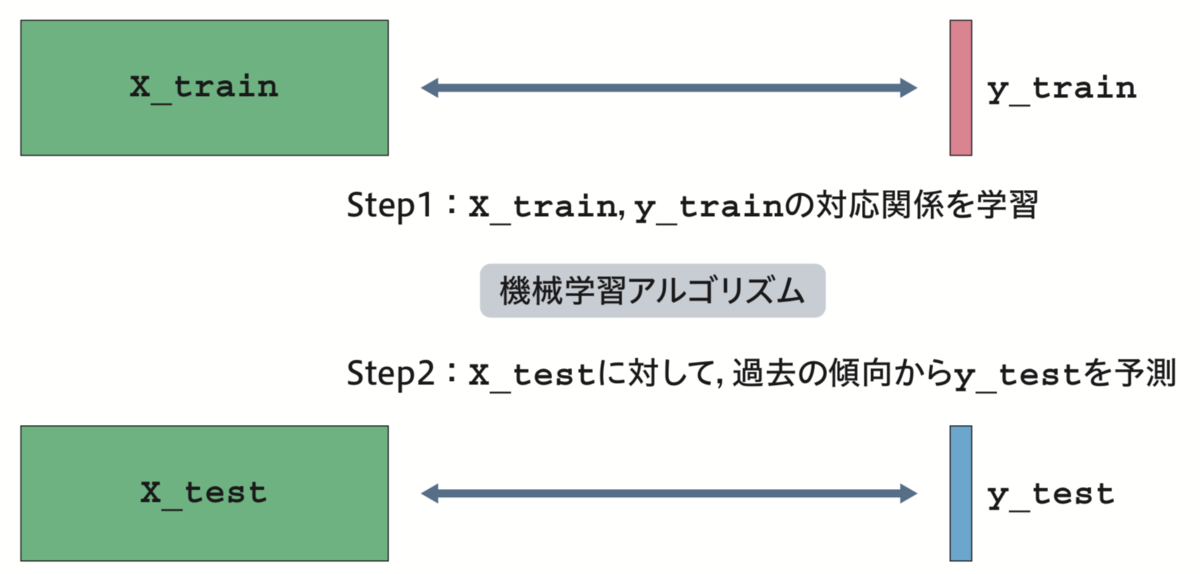
石原ら, 『PythonではじめるKaggleスタートブック』, 講談社
最初のアプローチ
知識に基づき、予測に効きそうな7つの特徴量を抽出しました。スクリーンプレイ中は、敵対するチームのプレーヤー間の距離が近づくことなどが推察されるためです。
- プレイヤー3人とボールの距離の最小値6通り
- フレーム数
機械学習アルゴリズムには、過去の実績から期待値が大きい「LightGBM」を利用しました。
性能の向上のために
その後、性能の向上のために数多くの手法を試し、結果的に優勝することができました。ここでは1位*6と2位*7の解法を比較し、特徴的だった点を列挙します。
- 「tsfresh」による特徴抽出
- ニューラルネットワークの利用
- アンサンブル(複数の予測値の混ぜ合わせ)
「tsfresh」による特徴抽出
- 時系列のデータセットから、最大値・最小値などの特徴を大量に抽出
- 特徴量の数: 11340 (4 agents * 2 dimensions + 6 distances between agents ) * 810
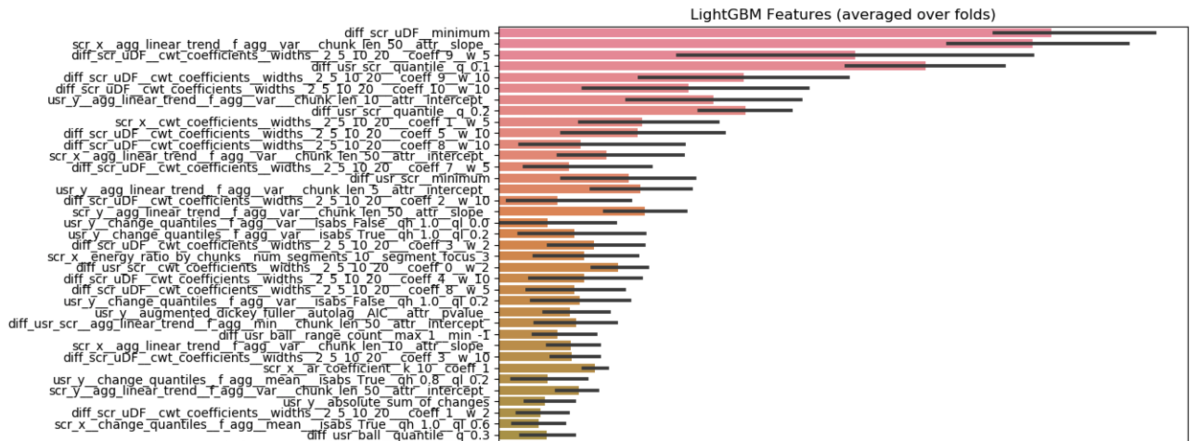
- 重要視された特徴量
ニューラルネットワーク
- 時系列の情報の最小値だけ使うと、情報を大きく失う
- 畳み込みニューラルネットワークを利用して、特徴を抽出
アンサンブル
複数の予測値の混ぜ合わせることで、性能の向上が確認されました。
