「#7 CA x atmaCup 2nd 振り返り回」でLTしました
「#7 CA x atmaCup 2nd 振り返り回」*1でLTしました。5位解法とともに、チームマージでの取り組みを具体的に紹介しました。
TF-IDFを用いた「Kaggle流行語大賞2020」
Kaggle Advent Calendar の8日目の記事です。
2018年、2019年に引き続き、今年もTF-IDFを用いた「Kaggle流行語大賞」を算出します。具体的には、2020年に公開されたNotebookのタイトル情報から、頻繁に登場した単語をランキング形式でまとめました。
2018年*1と2019年*2は「探索的データ分析(Explanatory Data Analysis, EDA)」が1位となりました。
それでは今年の結果を見ていきましょう。
集計方法
概ね昨年と同様の方法を採用しました。一連の処理はKaggleのNotebook*3にて公開しています。
データセット
「Meta Kaggle」*4のデータセット「Kernels.csv」を利用しました。公開されているNotebookの公開日・URLなどの情報が格納されています。
NotebookのURLは、ユーザが付けたタイトルに基づいて決まります。下図のように「Simple lightGBM KFold」というタイトルの場合は「simple-lightgbm-kfold」です。
Notebookの絞り込み
一定の評価を受けたNotebookに絞り込むため、次の処理を実施して「Voteを1以上得たNotebook」に集計対象を限定します。
kernels = kernels.query('TotalVotes > 0')
年ごとに分割
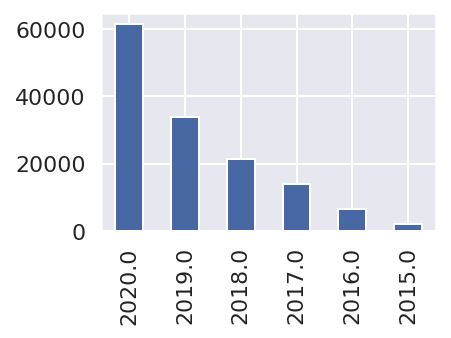
「公開年」別に集計すると、次のようになりました。公開されたNotebookは年々増加しています。
kernels['Date'] = pd.to_datetime(kernels['MadePublicDate']) kernels['Date'].dt.year.value_counts().plot.bar()
TF-IDFを計算
最後に、年を文書、タイトルを文の単位として捉えて「TF-IDF」を計算します。詳細は割愛しますが、多くの年で出現する語(一般的な語)は重要度が下がり、特定の年にしか出現しない単語の重要度は上がるような計算を施すことになります。あらかじめnltk.corpus内の英語のstopwordsを指定して、a, the, ofなどの一般的すぎる単語は取り除いています。
昨年までは筆者の判断でKaggle特有の一般的な単語やコンペのタイトル名に含まれる単語などを除外していましたが、今年は恣意性を排除するために特別な処理は止めました。
from nltk.corpus import stopwords from sklearn.feature_extraction.text import TfidfVectorizer stopWords = stopwords.words("english") vectorizer = TfidfVectorizer(stop_words=stopWords)
結果発表
2020年のTF-IDFの値で降順にソートした上位10件を以下に示します。2020年の首位は、突如現れた「covid」でした。「COVID19 Global Forecasting (Week 1) 」コンペ*5や「OpenVaccine: COVID-19 mRNA Vaccine Degradation Prediction」コンペ*6など、COVID-19を題材にしたコンペが複数開催されたのが要因だと考えられます。6位の「19」も、COVID-19から起因するものでしょう。
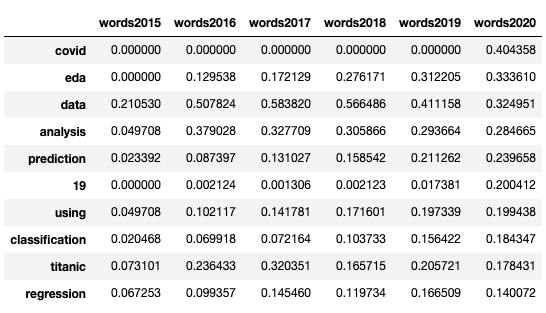
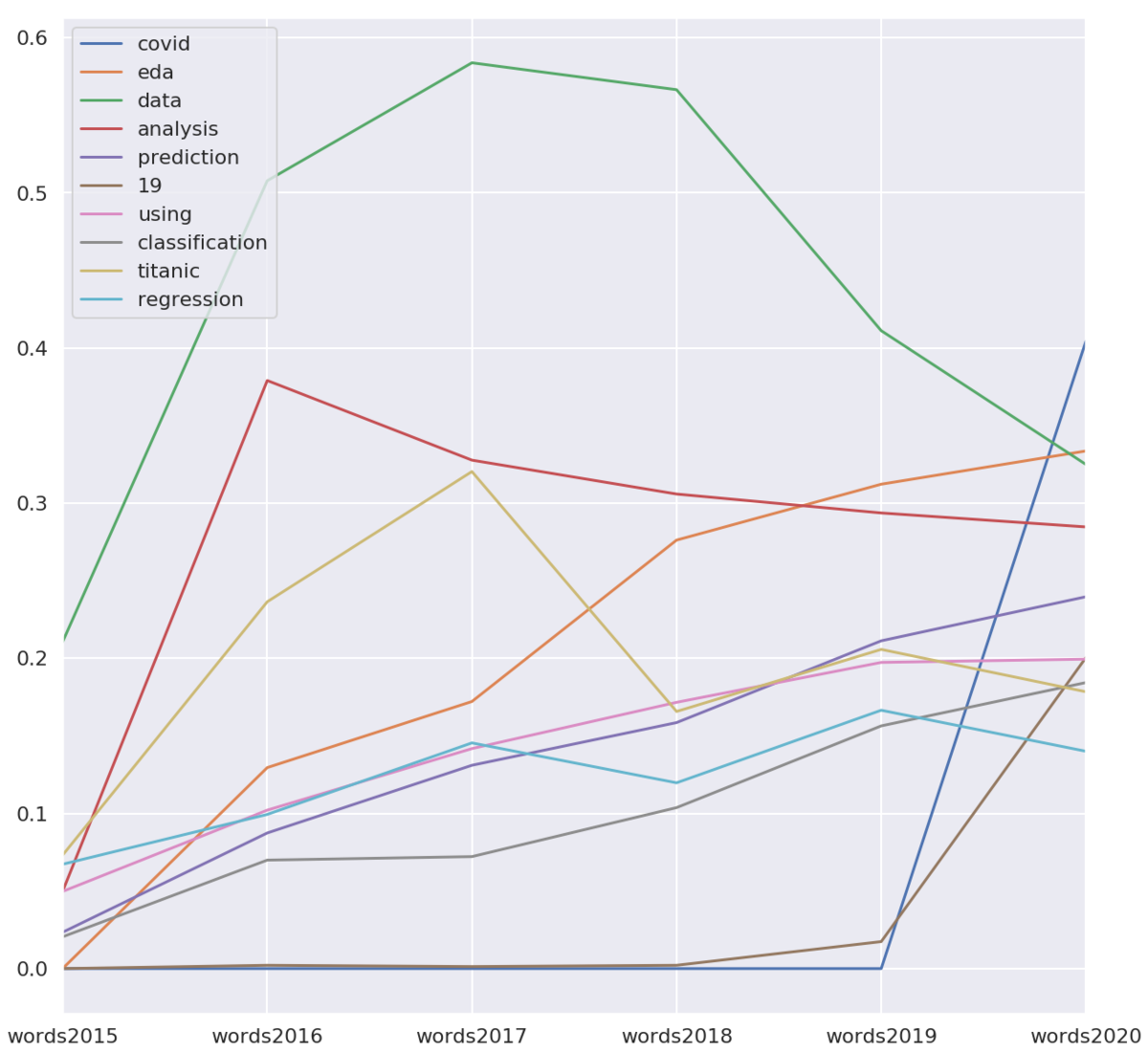
年次の推移は次の通りです。「covid」「19」が2020年に大きくスコアを伸ばしていると分かります。「data」「analysis」を除き2年連続で首位を守ってきた「eda」は、2位になりました。今年は「data」「analysis」を上回りましたが、それ以上にCOVID-19が流行していたという結果でした。
初学者向けコンペの「titanic」は、2015〜2017年に「data」「analysis」を除き1位になっていました。2018年以降は、徐々に順位を落としています。
おわりに
本記事では昨年に引き続き、TF-IDFを用いた「Kaggle流行語大賞」を算出しました。
今年1年も存分に楽しませてもらったKaggleに感謝しつつ、来年もKaggleを楽しんでいきたいです。
ニュースメディアでの機械学習活用事例について「Google Developers ML Summit」で登壇(12月3日)
12月3日に「Google Developers ML Summit」に登壇します。もう1年近く経ってしまった「Kaggle Days Tokyo」の話も含めて、会社での機械学習の活用事例を紹介する予定です。17:10-18:00の枠で、質問も受け付ける予定です。ご興味ある方はぜひご覧ください。
ニュースメディアでの機械学習活用事例 ー Kaggle コンペ開催を題材にー
Basketball Behavior Challenge 1st Place Solution
本記事について
- 「スポーツアナリティクス Advent Calendar 2020」*1の1日目の記事です。
- 12月13日開催の「Sports Analyst Meetup #9」*2で発表予定の内容をまとめました。
概要
- 2019年12月〜2020年9月に開催されていた「Basketball Behavior Challenge: BBC2020」*3の1位解法の紹介
- 時系列の座標データから「スクリーンプレイ」があったか否かを判定するコンペ
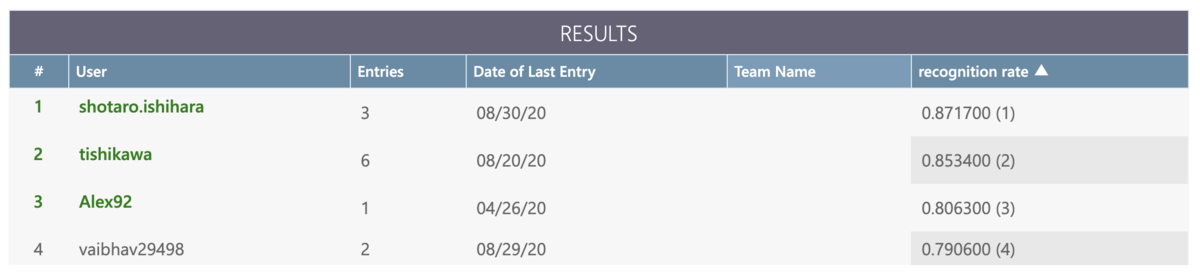
自己紹介
- 「Sports Analyst Meetup (spoana)」の運営メンバー
- 本業はメディア企業のデータサイエンティスト
- 本コンペは、spoana #7のLT発表で知った(アーカイブ)*4
- 共著に『PythonではじめるKaggleスタートブック』(講談社)*5
データの概要
バスケットボールの1プレイずつ切り取った座標データが提供されました。各プレイでは、同じチームの2プレイヤー scr と usr と相手チームのプレイヤー uDF、およびボール bal のx軸とy軸の値がフレーム単位で与えられています。
frame scr_x scr_y usr_x usr_y uDF_x uDF_y bal_x bal_y 0 2.89 4.74 5.49 1.5 2.78 5.22 6.98 12.7 1 2.88 4.7 5.52 1.51 2.8 5.2 7.08 12.52 2 2.87 4.67 5.54 1.53 2.82 5.19 7.13 12.35 3 2.86 4.65 5.56 1.54 2.84 5.17 7.08 12.37 ...
正例のデータはスクリーンプレイを含み、負例のデータは含みません。具体的にどのようなデータなのかは、コンペページの可視化が分かりやすいです。
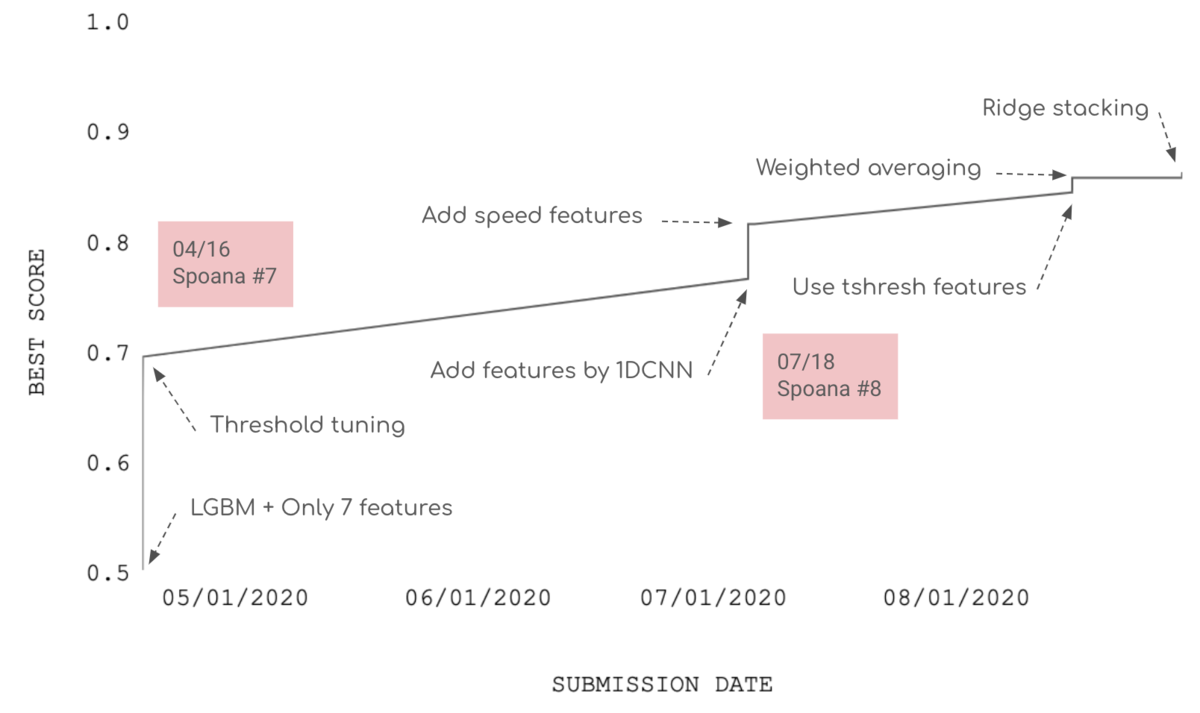
スコアの推移
次図は、私のスコアの推移です。最終的には、約0.87の正答率で未知のデータの結果を当てることができました。
機械学習の教師あり学習
予測モデルの作成には、機械学習の教師あり学習と呼ばれる技術を利用しました。次図に示す通り、答えが分かっているデータから「特徴量」 X_train と正解 y_train のペアを作成し、未知のデータ X_test に対する予測を導く考え方です。
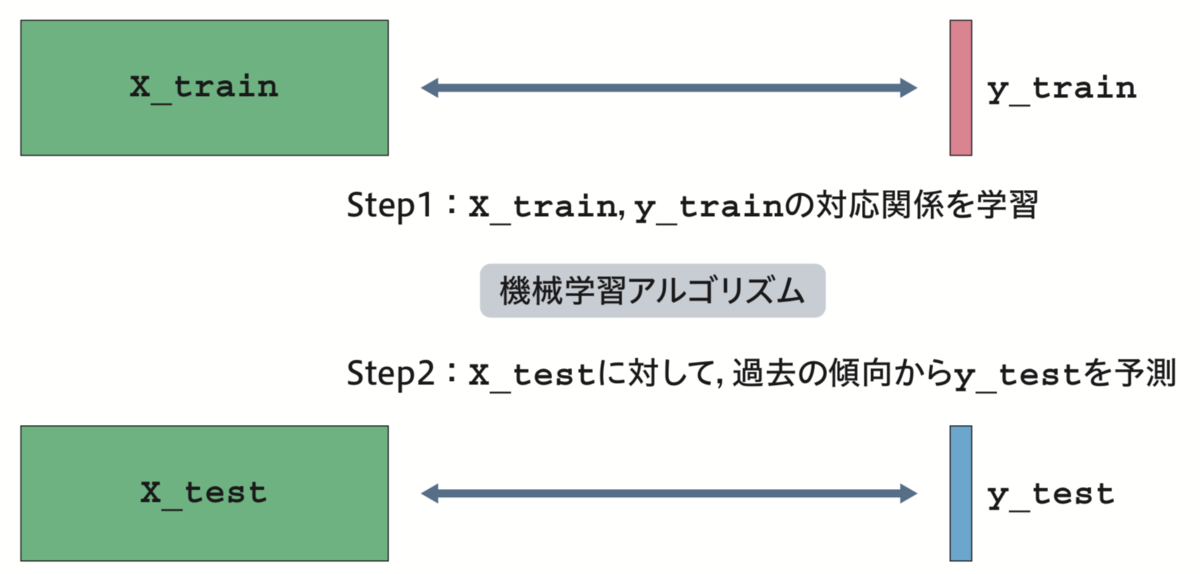
石原ら, 『PythonではじめるKaggleスタートブック』, 講談社
最初のアプローチ
知識に基づき、予測に効きそうな7つの特徴量を抽出しました。スクリーンプレイ中は、敵対するチームのプレーヤー間の距離が近づくことなどが推察されるためです。
- プレイヤー3人とボールの距離の最小値6通り
- フレーム数
機械学習アルゴリズムには、過去の実績から期待値が大きい「LightGBM」を利用しました。
性能の向上のために
その後、性能の向上のために数多くの手法を試し、結果的に優勝することができました。ここでは1位*6と2位*7の解法を比較し、特徴的だった点を列挙します。
- 「tsfresh」による特徴抽出
- ニューラルネットワークの利用
- アンサンブル(複数の予測値の混ぜ合わせ)
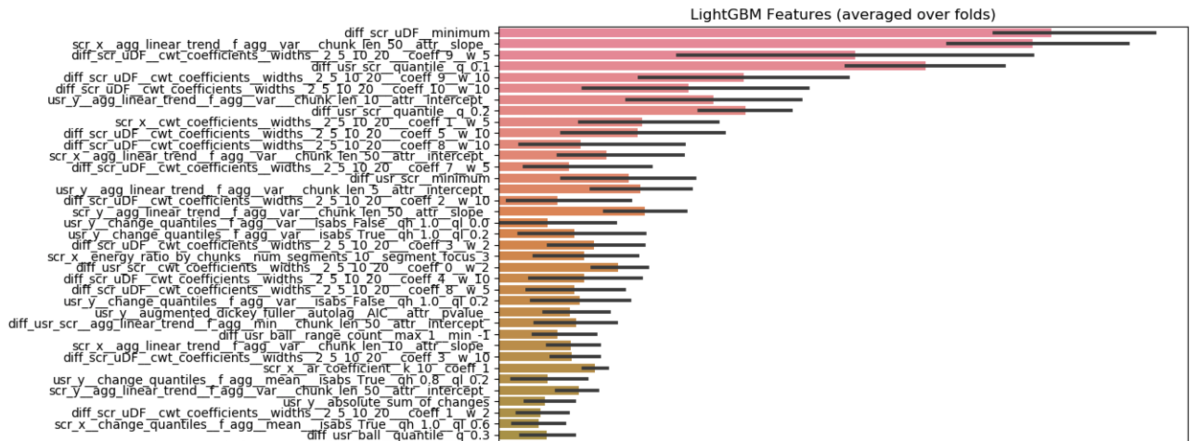
「tsfresh」による特徴抽出
- 時系列のデータセットから、最大値・最小値などの特徴を大量に抽出
- 特徴量の数: 11340 (4 agents * 2 dimensions + 6 distances between agents ) * 810
- 重要視された特徴量
ニューラルネットワーク
- 時系列の情報の最小値だけ使うと、情報を大きく失う
- 畳み込みニューラルネットワークを利用して、特徴を抽出
アンサンブル
複数の予測値の混ぜ合わせることで、性能の向上が確認されました。

まとめ
M-1グランプリ2020の2回戦動画を観た
M-1グランプリ2020の2回戦動画がGyaoとYouTubeで全公開されていたので、合格者を中心にザッと目を通しました。
昨年の準決勝を観に行くくらいには以前からお笑い好きでしたが、今年は在宅の時間が増えたことも相まって、その傾向が加速しました。
明日M-1準決勝を見に行く、楽しみ🤣 pic.twitter.com/9rYhKRzBwR
— u++ (@upura0) December 3, 2019
せっかくなので、気になったコンビを列挙してみました。末尾に★を付けているのが、現時点での決勝予想9組です。予選は動画配信されることもあり、ニューヨークやラランドなど一押しのネタを温存していると思われる組もあり、あくまで現時点での所感です。挙げているコンビで例年の準決勝進出数の25+1を超えているので、なかなか悩ましいなと感じました。
- さや香★
- オズワルド★
- インディアンス★
- 見取り図★
- マヂカルラブリー★
- くらげ★
- 赤もみじ★
- ロングコートダディ★
- もも★
- ななまがり
- ラランド
- ニューヨーク
- ニッポンの社長
- ゆにばーす
- デニス
- わらふぢなるお
- からし蓮根
- 滝音
- ダイタク
- 吉田たち
- ミキ
- アキナ
- 金属バット
- 藤崎マーケット
- 三四郎
- すゑひろがりず
- 東京ホテイソン
- トム・ブラウン
- ぺこぱ
- アインシュタイン
- 令和ロマン
- 錦鯉
- ダイヤモンド
過去の決勝経験者の中では、今年の歌ネタ王決定戦を制したさや香が仕上がっている印象です。昨年の決勝進出組も軒並み安定感があり、3組程度は2年連続の出場になる予感がします。その他、今年はマヂカルラブリーにも期待しています。
M-1では昨年、敗者復活を除く9組中7組が初めての決勝となり、知名度に依存しない若返りが図られている雰囲気を感じます。今年の初進出候補としては、くらげ・赤もみじ・もも・ロングコートダディが個人的な推しです。
良い意味で期待を裏切られたコンビがデニスです。少し昨年王者・ミルクボーイの雰囲気を感じるネタで評価が分かれる部分はありそうですが、とても面白い漫才でした。結成15年目ラストイヤーのコンビも当然注目です。今年は有名どころだと、藤崎マーケット・三四郎・スリムクラブあたりが該当します。2回戦動画からも、芸歴15年以上のベテランが本意気で取り組んでいる様子が伺えました。藤崎マーケットは緊張からか噛む機会が多く、三四郎の小宮がかなりの熱力を見せていました。
徒然なるままに趣味の感想を垂れ流してしまいましたが、この情勢の中で今年もM-1が開催されていることに感謝しつつ、今後の準々決勝以降も大いに楽しみにしています。
データサイエンティスト協会シンポジウムのKaggleセッションに登壇(11月10日)
11月10日にデータサイエンティスト協会シンポジウムで、毎年恒例のKaggleセッションを実施します。
11月10日にデータサイエンティスト協会シンポジウムで、毎年恒例のKaggleセッションを実施します。今年のテーマは「Kaggler枠」で、企業によるKaggler支援を掘り下げていきます。私は司会を務めます。オンライン開催で、学生は無料です。ぜひご参加ください!https://t.co/xObvpII98l pic.twitter.com/FkXb4Qmrzd
— u++ (@upura0) October 29, 2020
今年のテーマは「Kaggler枠」で、企業によるKaggler支援を掘り下げていきます。私は司会を務めます。オンライン開催で、学生は無料です。今回、ありがたいことに企画のアイディア出しにも携わらせていただきました。かなり豪華なメンバーにご登壇いただけることになり、嬉しい限りです。
Kaggleセッション以外にも、因果探索・競馬AIなど、興味深い講演が盛りだくさんです。ご興味ある方は、ぜひご覧ください。
日本語BERTを用いた会社名の埋め込み
以前に参加したNishika「財務・非財務情報を活用した株主価値予測」コンペ*1で検討していたタイトルの技術について、別コンペで使う可能性があったので改めてコードを整理していました。結局使わなかったですが、せっかくまとめたのでブログ記事として供養しておきます。
手法
会社名などラベル名に意味がある場合、何らかの形でそのラベル名のベクトル表現を獲得し特徴量として追加することは性能向上に繋がる可能性があります。今回はラベル名が日本語の会社名なので、日本語で事前学習されたBERTを用いて埋め込み表現を獲得しました。
結果
処理の詳細はソースコードをご確認ください。結果として、例えば「三井住友建設株式会社」のベクトル表現に類似している企業名として「住友不動産株式会社」「住友商事株式会社」「第一建設工業株式会社」などの文字列が似ているラベル名が挙がっています。なお実験のためのデータセットとしては、冒頭述べたコンペでも使われた「CoARiJ: Corpus of Annual Reports in Japan」*2を採用しています。
