「競プロ忘年会 in 東京 2018」のメモと感想 #kyopro
競技プログラミングの勉強&モチベーション・アップのため、「競プロ忘年会 in 東京 2018」に参加してきました。

- 「unit propagationと最大流と分枝限定法」@wata_orz
- 「アメリカ大学院留学で後悔していること: 競技プログラミング編」@katryo
- 「最近日本人が無双してる某マイナー競技について」@snuke_
- 「入社してからやってるグラフコンパイラ的なやつを、競プロの人が興味持ちそうなとこを中心に説明するので、入社をご検討下さい(仮)」@shinh
- 「歴代のやばいKagglerたちのアルゴリズムと bit-wise GBM」@smly
「unit propagationと最大流と分枝限定法」@wata_orz
[1704.02700] 0/1/all CSPs, Half-Integral $A$-path Packing, and Linear-Time FPT Algorithms
- 上記のご自身の論文の紹介
- 最初少しだけ付いていったが、一気に理解が及ばず振り落とされた orz
「最近日本人が無双してる某マイナー競技について」@snuke_
「入社してからやってるグラフコンパイラ的なやつを、競プロの人が興味持ちそうなとこを中心に説明するので、入社をご検討下さい(仮)」@shinh
今日のスライドです。面白そうと思った人連絡ください https://t.co/nk5YHErOCk 質疑応答で安易にLearn or Dieとか言ったのは微妙でした。あれは僕の中では「CSのあらゆる分野に精通〜」と同様に、努力目標であり、そうありたいものだなあ(できないけど)という心意気というように解釈しています
— shinichiro hamaji (@shinh) 2018年12月16日
TF-IDFを用いた「Kaggle流行語大賞2018」【kaggle Advent Calendar 14日目】
本記事は、kaggle Advent Calendar 2018の14日目の記事です。12日目で最後の予定でしたが、穴が空いていたので2日ぶり6回目の投稿です。
はじめに
本記事では、年の瀬ということで「Kaggle流行語大賞2018」という題材に取り組みます。
具体的には、今年に公開された全てのKernelのタイトルを収集し、単語ごとの登場回数を計算しました。冠詞や代名詞などの一般的な単語を除外し、さらにTF-IDFを用いて2018年に特に多く登場した単語を特定することで、栄えある「Kaggle流行語大賞2018」を決定したいと思います。
データ収集
今回は「Meta Kaggle」という、Kaggle公式が1日ごとにデータを更新しているメタ情報を利用します。最新のデータが12月12日の時点のcsvをダウンロードしました。
"Kernels.csv" 内に、Kernelの公開日・URLなどの情報が格納されていました。
KaggleのURLは、最後の/以下が「Kernelのタイトルを全て小文字に変換し、半角スペースをハイフンで置換した文字列」になっています。下図のように「Simple lightGBM KFold」というタイトルの場合は「simple-lightgbm-kfold」です。

全てが小文字に変換されている点は、集計を考える上で非常に都合が良いです。例えば「lightGBM」と「LightGBM」のような表記ブレを気にすることなく単語の登場回数を計算できます。今回は、このURLを利用して分析を進めることにします。
ちなみに、Kaggle APIの利用も検討しました。
しかし、下記のようなシェルスクリプトでデータを取得しようとしたところ、数日程度前までのデータまでしか遡ることができませんでした。
for i in `seq 1 100` do kaggle kernels list --sort-by 'dateCreated' -v -p $i >> data.csv done
データの加工
最初に、対象とするKernelを「Vote数が0より大きい」という条件で絞り込みます。Vote数が0のKernelを取り除くことで、ある程度の質を担保したいという意図があります。
kernel = kernel[kernel['TotalVotes'] > 0]
あとは年ごとに、タイトルに含まれる単語をリストに格納していきます。
kernel['Date'] = pd.to_datetime(kernel['MadePublicDate']) kernel2018 = kernel[kernel['Date'].dt.year == 2018.0].reset_index() words2018 = [] for _ in (kernel2018['CurrentUrlSlug']): words2018 += _.split("-")
上記を実行することで、word2018というリストに、2018年に公開された全てのKernelのタイトルに含まれる単語がまとめて格納されます。
例えば以下の3つのタイトルのKernelがあった場合、word2018は次のようになります。2つのKernelで登場する"analysis"はリスト内に2回登場しています。
- This is my first analysis
- Wonderful analysis one
- hello world
word2018 = [ "this", "is", "my", "first", "analysis", "wonderful", "analysis", "one", "hello", "world"]
比較のため、同様に2017年、2016年、2015年分のリストも作成しました。
単語の登場回数
最初に、単純にリスト内の登場回数を見てみます。出力結果は、上位25件を抜粋しました。
import collections
c2018 = collections.Counter(words2018)
c2018.most_common()
[('data', 2749),
('and', 1691),
('with', 1614),
('analysis', 1413),
('of', 1187),
('eda', 1151),
('for', 872),
('titanic', 814),
('challenge', 812),
('in', 796),
('using', 786),
('to', 749),
('the', 742),
('prediction', 736),
('cleaning', 654),
('day', 647),
('model', 624),
('1', 620),
('learning', 603),
('on', 537),
('0', 536),
('a', 528),
('regression', 517),
('simple', 511),
('keras', 504),"data"や"analysis"といったKaggleの文脈では当たり前の単語や、"and", "with", "of"などの自然言語処理の世界ではStop wordsと呼ばれるような単語が上位に来ています。
また同様に2017年版の上位25件を見てみると、似たような顔ぶれが登場しているような印象を受けます。単純な登場回数の上位を「流行語」と評価するのは、あまり適切ではなさそうです。
[('data', 2047),
('analysis', 1131),
('titanic', 1102),
('and', 1098),
('with', 1020),
('of', 957),
('day', 786),
('the', 713),
('0', 709),
('in', 698),
('to', 603),
('for', 538),
('eda', 520),
('regression', 496),
('challenge', 488),
('a', 483),
('using', 481),
('prediction', 432),
('on', 431),
('lb', 421),
('science', 415),
('python', 413),
('5', 396),
('simple', 394),
('r', 392),
('exploration', 375),
TF-IDFの計算
上記の考察を踏まえて「Kaggle流行語大賞2018」を決めるに当たって、以下の2つの処理を実施します。
- "data"や"analysis"といったKaggleの文脈では当たり前の単語や、"and", "with", "of"などの自然言語処理の世界ではStop wordsと呼ばれるような単語の除去
- 単純な登場回数ではなく、他の年にあまり出てこない単語を重要視して評価
前者について具体的には、NLTKというパッケージで定義されているStop wordsに加え、自分自身で消去すべきと考えた単語を取り除きます。デフォルトの定義に追加した単語は"data", "analysis", "using"の3つです。
from nltk.corpus import stopwords stopWords = stopwords.words("english") stopWords.append('data') stopWords.append('analysis') stopWords.append('using')
後者については、まさにこのような考え方で定義された「TF-IDF」を用います。詳細は巷に解説記事が溢れているので割愛しますが、多くのグループで出現する語(一般的な語)は重要度が下がり、特定のグループにしか出現しない単語の重要度は上がるような計算を施すことになります。
ここで、TfidfVectorizerの引数に「stop_words = stopWords」を与え、先に定義したStop wordsを取り除きました。
import numpy as np from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer(stop_words = stopWords) X = vectorizer.fit_transform(data).toarray()
TF-IDFに基づく「Kaggle流行語大賞2018」
2018年のTF-IDFの値で降順にソートした上位20件を以下に示します。
df = pd.DataFrame(X.T, index = vectorizer.get_feature_names(), columns = ['words2015', 'words2016', 'words2017', 'words2018']) df.sort_values('words2018', ascending=False).head(20)

単純に単語の登場回数を計算した場合と比べ、Stop wordsが除去され、かつ他の年にあまり出てこない単語を重要視した結果となっていると分かります。例えば、3位の"scavenger"という単語は単純な登場回数だけで判断すると430回で30位に相当しますが、2018年になって登場した単語なので、TF-IDFを用いた場合には上位にランクインしています。
ちなみに、"scavenger"は今年に公開されたKaggle内の「SQL Scavenger Hunt Handbook」というコース?の名称の一部だと思われます。
SQL Scavenger Hunt Handbook | Kaggle
この結果を、下の折れ線グラフで示します。

栄えある1位には"eda"が輝きました。2016年から登場し始めた単語で、2017年から更に登場回数が増えていきました。探索的データ分析(Exploratory data analysis)という考え方が徐々に浸透しつつあると読み取れるかと思います。
一方で、2017年に1位だった"titanic"は4位に後退しました。2012年に公開されたKaggleの有名なチュートリアルですが、流石に陰りが見え始めてきたということかもしれません。
Titanic: Machine Learning from Disaster | Kaggle
その他気になるところとしては、"cnn"が着実に順位を上げてきています。
Kaggleでソロ銀メダルを取った時にスマホでしていたこと【kaggle Advent Calendar 12日目】
本記事は、kaggle Advent Calendar 2018の12日目の記事です。
少しネタ要素が強いですが、Kagglerあるあるな記事だと思います。
今年の8月に終了した「Santander Value Prediction Challenge」にて、私はソロで銀メダルを獲得できました。

言わずもがな、プライベートの相当な時間をこのコンペに捧げたのですが、捧げたのは必ずしもPCに向かっている時間だけではありません。コンペ終盤に差し掛かってくると、通勤時間やちょっとした隙間時間でもKaggleに取り組みたくなります。[要出典]
本記事では、私がSantanderコンペの終盤時にスマホでしていた3つの取り組みについて、紹介したいと思います。
1. Twitterを見る
正直特に意識せずにやっていることですが、Twitterを追っているだけでも多くの情報が得られます。
もちろんKaggleではPrivate Sharingが禁止なのですが、例えば自分と同じコンペに参加している方がLeaderboardを登っていく様子を見るだけでも、モチベーションを高められる利点があります。また高スコアのKernelやリークなどが公開された場合はTwitterでも話題になるので、重要な情報を見落とす可能性を低くできます。
僕の場合は、次のようなKagglerを集めたTwitterリストを作成しています。このリストはコンペ参加中に限らず、いつも定期的に確認するようにしています。
2. メール通知でKaggleのdiscussionsを追う
Kaggleの公式の機能として、discussionsの「購読」が可能です。この設定をしておくことで、自分が参加しているコンペのdiscussionに何かしらの投稿があった際に、メールアドレスに通知を飛ばすことができます。
詳細は下記の記事にまとめられています。
コンペが盛り上がってくると結構な頻度でメールが飛んでくるので、全ての通知を追うのはかなり難しいかもしれません。しかし量をこなすことで私の場合は英語を読むことへの嫌悪感も払拭でき、熟読すべきかの判断を付ける練習にもなりました。
特にSantanderコンペはdiscussionsでの議論を追うことがメダル獲得に直結するようなコンペだったので、PCに向かっている時間以外でも議論の状況を確認できたのは良かったと思います。「メール通知が来ていない」=「discussionsの更新がない」ということなので、ある意味で心の安寧を担保できる仕組みにもなっていました。
3. Kaggle API&LINE APIでKaggleのkernelsを追う
コンペも終盤に差し掛かってくるとKernelの公開も注視したいという感情が湧いてきました。しかし現状、公式ではKernelsへの投稿を通知する機能はありません。
そこでKaggle APIとLINE APIを用いて、Kernelへの投稿を検知してLINEに通知を送る仕組みを実装しました。詳細は下記の記事にまとめています。
実際のLINEの画面は以下の通りです。この仕組みを実装したことで、特に「高スコアのKernelが出ていないか」を常に確認できる状態になっていました。

おわりに
本記事では、私がソロで銀メダルを獲得したSantanderコンペの終盤時にスマホでしていた3つの取り組みについて、紹介しました。
Twitterなどを眺めていると、スマホのブラウザでKaggleのKernelを開いてコーディングしている人もいるようです。これは好みの問題かと思いますが、私はコーディングはPCでやった方が明らかに効率が良いので、PCを開けない時間は完全に切り分けて「情報収集や思考の時間」としていました。
おまけ
PCを開けない時間に思いついたことをTo doリストに入れていたのですが、入力が手軽かつデバイス間の同期が容易な「Todist」が非常に便利でした。ここ4, 5年くらい、私のTo do管理には「Todist」を使っていて、個人的には日常に欠かせないサービスとなっています。
遺伝的プログラミングによる特徴量生成でLightGBMの精度向上【kaggle Advent Calendar 11日目】
本記事は、kaggle Advent Calendar 2018の11日目の記事です。
執筆のきっかけ
先日参加したKaggle Tokyo Meetup #5 の ikiri_DS の発表「Home Credit Default Risk - 2nd place solutions -」にて、遺伝的プログラミングで生成した特徴がLocal CV、Public LB、Private LBの全てで精度向上に貢献したという話がありました。
遺伝的プログラミングや遺伝的アルゴリズムは、大学の学部時代から興味があり、ブログでも何度か取り上げてきました。しかしKaggleなどで試したことはなかったので、自分で手を動かして検証してみようと考えた次第です。
遺伝的プログラミングによる特徴量生成
遺伝的プログラミングによる特徴量生成の理論的な背景や実装については、昨年に執筆された下記の記事が非常によくまとまっています。
ただし本記事では、Kaggleに用いるという観点から、この手法で生成した特徴量がKaggleでよく使われる分類器「LightGBM」でも効果を発揮するか分からない点が気になりました。
本記事では、この点について実験で検証したいと思います。
LightGBMによる実験
実装はGitHubで公開したので、興味ある方はご参照ください。
最初に、実験に用いるデータセットを作成します。特徴量が10個ある10000行のDataFrameを作成しました。20%をtestデータとして分割しておきます。
from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split # サンプルデータの生成 X, y = make_classification(n_samples=10000, n_features=10, n_informative=5, n_redundant=0, n_repeated=0, n_clusters_per_class=8, random_state=123) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123) # LightGBM用の分割 X_train2, X_valid, y_train2, y_valid = train_test_split(X_train, y_train, test_size=0.2, random_state=123)
特徴量生成前
まずは単純にLightGBMで精度を検証してみます。
import lightgbm as lgb import matplotlib.pyplot as plt lgb_train = lgb.Dataset(X_train2, y_train2) lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train) lgbm_params = { 'learning_rate': 0.1, 'num_leaves': 8, 'boosting_type' : 'gbdt', 'reg_alpha' : 1, 'reg_lambda' : 1, 'objective': 'regression', 'metric': 'auc', } # 上記のパラメータでモデルを学習する model = lgb.train(lgbm_params, lgb_train, # モデルの評価用データを渡す valid_sets=lgb_eval, # 最大で 1000 ラウンドまで学習する num_boost_round=1000, # 10 ラウンド経過しても性能が向上しないときは学習を打ち切る early_stopping_rounds=10) # 特徴量の重要度をプロットする lgb.plot_importance(model, figsize=(20, 10)) plt.show()
[1] valid_0's auc: 0.743222 Training until validation scores don't improve for 10 rounds. [2] valid_0's auc: 0.774293 [3] valid_0's auc: 0.786269 [4] valid_0's auc: 0.796968 [5] valid_0's auc: 0.798784 (中略) [172] valid_0's auc: 0.855702 [173] valid_0's auc: 0.855937 [174] valid_0's auc: 0.85584 Early stopping, best iteration is: [164] valid_0's auc: 0.856409

testデータで確認したところ、AUC=0.854653164841を得ました。
from sklearn.metrics import roc_auc_score # テストデータを予測する y_pred = model.predict(X_test, num_iteration=model.best_iteration) # auc を計算する auc = roc_auc_score(y_test, y_pred) print(auc)
特徴量の生成
遺伝的プログラミングを用いた特徴量の生成に関しては、先の記事からほとんど変更していません。ベースのモデルはL2正則化ロジスティック回帰、評価方法はtrainデータの5-foldクロスバリデーションAUCを利用しています。
ここでのベースのモデルもLightGBMなどの勾配ブースティング系に変更しようと試してみましたが、計算量が膨大になってしまうため、比較的単純なモデルのままとしました。
生成された特徴量は以下の通りです。
### Generated feature expression mul(sub(add(mul(ARG9, ARG2), cos(neg(ARG6))), neg(ARG6)), sub(ARG7, cos(cos(neg(ARG6))))) mul(neg(ARG10), mul(ARG9, ARG8)) sub(add(ARG1, ARG8), add(mul(add(ARG2, ARG6), ARG8), cos(protectedDiv(ARG10, ARG3)))) sub(sub(sub(neg(mul(ARG9, ARG12)), cos(ARG9)), cos(ARG9)), mul(ARG2, ARG12)) mul(add(add(ARG6, neg(ARG7)), ARG8), add(sin(ARG6), neg(ARG7))) sin(cos(add(ARG8, ARG2))) cos(cos(add(cos(ARG9), sin(sin(ARG2))))) mul(sub(ARG10, mul(mul(ARG7, ARG2), cos(ARG6))), ARG16) mul(ARG14, ARG8) mul(sub(sub(ARG14, ARG9), sin(ARG6)), add(ARG9, ARG2)) mul(ARG11, cos(ARG16)) sin(cos(ARG7)) mul(add(cos(ARG9), tan(ARG21)), ARG8) cos(ARG22) mul(sub(ARG23, ARG21), sub(sin(ARG9), add(sub(sin(ARG9), add(ARG13, ARG3)), ARG3))) mul(add(add(ARG21, neg(neg(ARG16))), ARG2), ARG23) mul(ARG2, neg(mul(ARG9, ARG9))) mul(cos(ARG14), ARG26) sub(mul(mul(cos(ARG13), ARG0), ARG26), mul(ARG17, ARG26)) mul(cos(ARG6), ARG2)
例えば「mul(cos(ARG6), ARG2)」は、「cos(特徴量6) × 特徴量2」という式で計算される特徴量を意味します。生成された特徴量を眺めてみると、人間ではなかなか思いつかないような式が生成されていると分かります。
10個の特徴量から新たに20個の特徴量を生成するのに、下記スペックのMacBook Proで1時間30分程度かかりました。元にする特徴量の数やDataFrameの行数によっては、かなりの時間がかかると見込まれます。

またtrainデータとtestデータに関する精度は、次の図のように向上していきました。

特徴量生成後
特徴量生成前と同様に、LightGBMで精度を検証しました。
[1] valid_0's auc: 0.752588 Training until validation scores don't improve for 10 rounds. [2] valid_0's auc: 0.770969 [3] valid_0's auc: 0.791902 [4] valid_0's auc: 0.796553 [5] valid_0's auc: 0.79827 (中略) [137] valid_0's auc: 0.866912 [138] valid_0's auc: 0.866721 [139] valid_0's auc: 0.866903 Early stopping, best iteration is: [129] valid_0's auc: 0.867409
testデータで確認したところ、AUC=0.877752818887 (> 0.854653164841)と、特徴量を加える前より高い精度を示しました。
特徴量の重要度を確認したところ、上位5番目から新規に追加した特徴量(インデックスが10以上のもの)が登場しています。

おわりに
本記事では、遺伝的プログラミングによる特徴量生成について、この手法で生成した特徴量がLightGBMを用いた場合でも効果を発揮すると確認しました。
ただし最大のボトルネックとして、計算時間の問題が残ります。遺伝的プログラミングでは大量の試行錯誤を実施するため、今回のさほど大きくないデータセットでも一定の時間が必要となりました。実際のコンペに投入するに当たっては、事前に特徴選択を実施するなどの対応が必要かもしれません。
『Kaggle Ensembling Guide』はいいぞ【kaggle Advent Calendar 7日目】
本記事は、kaggle Advent Calendar 2018の7日目の記事です。
TwitterでこのAdvent Calendarに書く話題を募集したところ、次のようなリプを頂きました。
あと Kaggle で多用される Ensemble のテクニックに関する記事も読んでみたいです。特に Stacking は巷に資料が少ない気がします。やるときの注意点などもあるとめっちゃ嬉しいです。
— もみじあめ (@momijiame) December 5, 2018
この話題については、私自身が記事を書くよりも、既にKaggleの一部界隈の人はご存知?の有名エントリ『Kaggle Ensembling Guide』があります。
https://mlwave.com/kaggle-ensembling-guide/
正直言って、これ以上のまとめを書くのは相当に骨が折れそうなので、今回は紹介記事という形にしたいと思います。(単なる日本語訳も需要がありそうですが、権利的な問題が把握できていないので、今回はやめておきます)
Kaggle Ensembling Guide

『Kaggle Ensembling Guide』は、その名の通り、Kaggleにおけるensembling(アンサンブル)の技法を紹介している記事です。
機械学習における「アンサンブル」は、複数のモデル(学習器)を組み合わせることで精度の高いモデルを作成する手法を意味します。『Kaggle Ensembling Guide』では「サブミットファイルによるアンサンブル」や「Stacked Generalization」、「Blending」といった様々な技法について、具体例と合わせて紹介がなされています。
この記事単体でも十分に価値があるのですが、さらに素晴らしい点はGitHub上でコードが公開されていることです。このコードを用いて実際に手を動かすことで、より一層理解が深まると思います。
アンサンブルの威力
さすがにリンク2つの紹介では味気ないので、本記事では最後にアンサンブルの威力を示す例を2つ提示したいと思います。
三人寄れば文殊の知恵
1つ目の例は、『Kaggle Ensembling Guide』の冒頭から引用します。
ここでは、10個のyに対して、0か1の二値分類を考えます。
つまりは
のような予想をする問題です。簡単のため、以後は右辺の括弧内だけを取り出して次のように表現したいと思います。次の例は「と
のみで1と予想した」という意味です。
0000100001
さて、ここで正解が全て1であるような問題を考えます。
1111111111
この問題に対して、モデルA・B・Cがそれぞれ次のような予測をしたとしましょう。
モデルA = 80% accuracy
1111111100
モデルB = 70% accuracy
0111011101
モデルC = 60% accuracy
1000101111
単純に一番良いモデルを選んだ場合、モデルAを採用すれば80%の正解率を得られる状況です。しかし、ここでアンサンブルを使うと80%以上の正解率を出すモデルを得ることができます。
今回使うアンサンブルは、非常に単純な「多数決」の技法です。のそれぞれで各モデルの予測を確認し、多数決で最終的な予測結果を導出します。
例えばについて、モデルAとモデルCは1を、モデルBは0を予測しています。そのため、最終的な予測結果は1とします。
同様に考えていくと、下記が最終的な予測結果です。
最終的な予測結果 = 90% accuracy
1111111101
なんと、基にした全てのモデルよりも高い正解率を得ることができました。
数式的な説明は『Kaggle Ensembling Guide』に記載があるので割愛しますが、それぞれのモデルの悪い部分を補完し合い、全体として良い予測結果が得られています。
「Avito Demand Prediction Challenge」(31stから9thへ)
2つ目は、先日開催された「Kaggle Tokyo Meetup #5」で発表された「Avito Demand Prediction Challenge」での事例を紹介します。
最終的には9位となったこのコンペについて、Koheiさんがアンサンブルに関して解法を説明しました。
単体モデルのベストスコアはprivate LBで31位相当でしたが、アンサンブルの技法の一つ「Stacked Generalization」を実施した結果、15位まで精度が向上したそうです。さらにpublic LBのスコアを用いて重みを計算し「Blenging」を実施した結果、最終的な9位のモデルが誕生したとのことでした。
詳細は発表資料をご覧いただければと思いますが、この「黒魔術」的な手法に会場は大いに盛り上がりました。
↓Twitterのハッシュタグでも盛り上がりが観測できます。
togetter.com
おわりに
本記事では『Kaggle Ensembling Guide』と言う名エントリを紹介し、具体的なアンサンブルの威力も紹介しました。
アンサンブルはKaggleなどのコンペにおける最後の一押しとして、大きな成果を発揮する場合があります。時には「実際の業務には役に立たない」と批判される対象にもなるものですが、個人的には「良くも悪くも機械学習コンペの特徴」と言えるものの一つだと思っています。
英語ではあるのですが、ぜひお時間のあるときにご一読をお勧めしたいです。
validationの切り方いろいろ(sklearnの関数まとめ)【kaggle Advent Calendar 4日目】
本記事は、kaggle Advent Calendar 2018の4日目の記事です。
はじめに
本記事では、3日目の記事で重要性を説明したCross Validationについて、「良いCV」となるvalidationのデータセットはどのようなものか考えてみたいと思います。
この話題については、scikit-learnのドキュメンテーションが非常に充実しています。本記事でも、ソースコードを大いに流用しました。
Visualizing cross-validation behavior in scikit-learn — scikit-learn 0.21.3 documentation
重要な視点
「良いCV」は何かを考える上で重要なのは、前回の記事で引用したbestfitting氏も述べていたように、データと解くべき問題を明確に理解することです。
具体的には、例えば以下のようなポイントが大切になります。
- 分類問題か回帰問題か
- 分類問題の場合、各クラスの数に偏りはないか
- 順番に意味のあるデータか(時系列データであるか)
このようなデータや解くべき問題に応じて、適切な手法でvalidationのデータセットをtrainのデータセットから切り出す必要があります。
scikit-learnに用意されている関数
今回はscikit-learnのドキュメンテーションの例に沿って、次のような3クラス分類のデータセットを考えてみます。説明のため、クラス0が水色、クラス1が橙色、クラス2が茶色とします。
クラスとは別の概念として、データセット全体は均等な10グループに分割されています。グループはなかなかイメージが付きづらいかもしれませんが、例えば「同じユーザのデータを一つのグループにまとめておく」といった使い方が想定できます。同じユーザのデータがtrainのデータセットとvalidationのデータセットの両者に存在すると、不当に精度が高くなる恐れがあるためです。
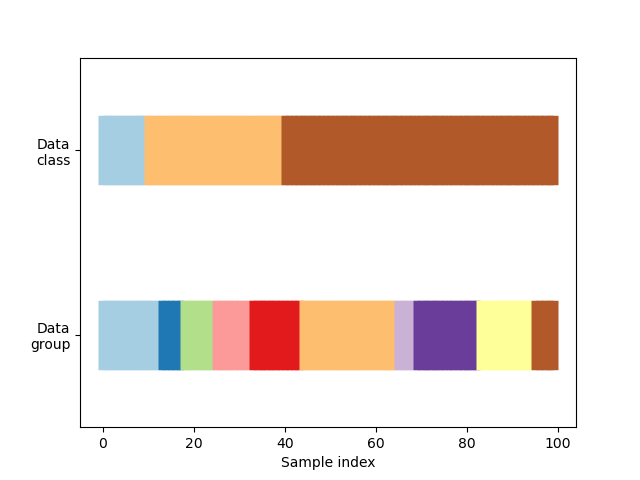
scikit-learnに用意されている関数を用いて、このデータセットをtrainのデータセットとvalidationのデータセットに切り分けてみましょう。
KFold
sklearn.model_selection.KFold — scikit-learn 0.21.3 documentation

上図のように、データセットを指定したn個に(デフォルトでは順序を変えることなく)分割します。赤がvalidationのデータセット、青がtrainのデータセットです。
個々の分割を見てみると、分割2と分割3では、全てのvalidationのデータセットがクラス2(茶色)になっています。一方で分割0のvalidationのデータセットにはクラス2(茶色)が全く含まれていません。全ての分割でクラスが偏った状況になっており、適切なスコアが得られないことが分かります。
StratifiedKFold
sklearn.model_selection.StratifiedKFold — scikit-learn 0.21.3 documentation

上図のように、データセット全体のクラスの偏りを保持しながら、データセットを分割できます。KFoldと比較して、このデータセットにおいては「良いCV」となっていると言えるでしょう。
GroupKFold
sklearn.model_selection.GroupKFold — scikit-learn 0.21.3 documentation
上図のように、同じグループが異なる分割パターンに出現しないようにデータセットを分割できます。GroupKFoldが必要な具体的事例は、iwiwiさんのスライドや動画が分かりやすいです。

ShuffleSplit
sklearn.model_selection.ShuffleSplit — scikit-learn 0.21.3 documentation

上図のように、ごちゃまぜで分割します。各分割でデータセットをシャッフルして考えているため、データの重複が許容されています。
GroupShuffleSplit
sklearn.model_selection.GroupShuffleSplit — scikit-learn 0.21.3 documentation

上図のように、グループ単位でランダムにvalidationのデータセットに割り当てるように分割します。GroupKFoldと比べると、例えば一番左のグループが一度もvalidationのデータセットとして使われていません。これは、ShuffleSplitと同様に各分割でデータセットをシャッフルして考えているため、データの重複(つまりは使われないデータの存在)が許容されるからです。
StratifiedShuffleSplit
sklearn.model_selection.StratifiedShuffleSplit — scikit-learn 0.21.3 documentation

上図のように、データセット全体のクラスの偏りを保持しながら、データセットを分割できます。GroupShuffleSplitとGroupKFoldの比較と同様、StratifiedShuffleSplitもStratifiedKFoldと比較すると、データの重複が許容されていると分かります。必ずしも全てのデータがvalidationのデータセットに一度使われるわけではありません。

回帰問題の場合
ここまで分類問題を例として扱ってきましたが、回帰問題の場合もこれらの分割方法が利用できます。回帰問題ではクラスという概念がありませんが、例えば目的変数を1変数でk-meansで適当に分類することで、擬似的にクラスを作成してStratifiedKFoldを用いることも可能です。
必ずしも「Trust CV」ではない
ここまでの議論では「trainのデータセットとtestのデータセットで各クラスの分布が似通っている」という前提に基づいて話を進めてきました。しかし時には、trainのデータセットとtestのデータセットで分布が異なる場合もあるかもしれません。
例えば極端な例ですが、trainのデータセットではクラス0:クラス1:クラス2 = 1:3:6 なのに、testのデータセットではクラス0:クラス1:クラス2 = 5:5:0 のような場合です。この場合には、どれほどtrainのデータと解くべき問題を明確に理解して「良いCV」、つまりはtrainのデータセットと分布が等しいvalidationデータセットを作成しても、意味がありません。
testのデータセットの分布はコンペ終了時まで分かりませんが、「良いCV」を作った自信があるにもかかわらずlocal CVとpublic LBのスコアに大きな乖離がある場合は、trainのデータセットとtestのデータセットで分布が異なることを仮定しても良いかもしれません。
このような状況では「Adversarial Validation」の利用も検討できます。以前に簡単にまとめた記事があるので、興味があればご参照ください。
Adversarial Validation
Cross Validationはなぜ重要なのか【kaggle Advent Calendar 3日目】
本記事は、kaggle Advent Calendar 2018の3日目の記事ということにします。本日、このAdvent Calendarに空きがあると気付いたので、穴埋めの形で急遽記事を執筆しました。僕が遅刻したわけではありません。
TwitterでこのAdvent Calendarに書く話題を募集したところ、次のようなリプを頂きました。
めぇっちゃ個人的な戯言なので適当に流して頂いて良いのですがバリデーションの切り方の話とか読みたいなぁと思います。
— icebee (@icebee__) December 4, 2018
本記事ではまず、そもそも「Cross Validationはなぜ重要なのか」について言及しようと思います。
Cross Validationの重要性
機械学習の文脈における「validation」は、一般的に「モデルの汎化性能の検証」を意味します。汎化性能とは「未知のデータに対する性能」のことです。
validationの重要性を確認するため、「validationがない場合」を想定して、簡単な例を見てみます。
validationがない場合
パッケージやデータの準備
import pandas as pd from sklearn import datasets, model_selection from sklearn.ensemble import GradientBoostingClassifier iris = datasets.load_iris() iris_data = pd.DataFrame(data=iris.data, columns=iris.feature_names) iris_label = pd.Series(data=iris.target) X_train, X_test, y_train, y_test = model_selection.train_test_split(iris_data, iris_label)
訓練と予測
clf = GradientBoostingClassifier(random_state=0)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
精度の検証
ここで、この予測結果の精度はどのように確認すれば良いでしょうか?

y_predとy_testを比較すれば良いと思うかもしれませんが、例えばKaggleではコンペ終了時までy_testの全容は分かりません。一部データはpublic LBに利用されておりスコアを確認できますが、以下の二つの問題があります。
- public LBで良いスコアが出ても、一部のデータのみに過学習した結果の可能性がある
- サブミットできる回数に制限がある
前者について、public LBに使われているデータはtestのデータセットの10〜30%が一般的で、仮に新しいハイパーパラメータや特徴量を使ってスコアが上がっても、一分のデータのみに効果がある「過学習」に陥っている可能性があります。
また、public LBにどのようなデータが使われているかも分かりません。極端な例ですが、二値分類の問題で0のラベルが付いたデータのみがpublic LBに使われている可能性もあります。この場合、仮にpublic LBで高いスコアを出すモデルが作成できても、そのモデルは1のラベルを当てる性能がどれだけあるか確認できていません。
後者について、Kaggleでは1日の提出回収が3〜5回とコンペごとに制限が決まっています。public LBのスコアは提出しないと分からないので、1日の提出回数分しかモデルや特徴量の試行錯誤ができない状況になってしまいます。
ホールドアウト検証を実行した場合
これらの問題に対応するのが、validationです。validationのためのデータセットは、trainのデータセットから分割することで作成します。

このvalidationのデータセットは、自分でtrainのデータセットから作成したため、全容を把握できています。validationのデータセットを「上手に」作成すれば、public LBのスコアよりも信頼性の高いスコアを得られると分かります。
またこのスコアは提出することなく、手元で確認可能です。自分の気の済むだけ試行錯誤を回し、良いスコアを得た場合に提出するような運用が可能です。
この例のような検証を「ホールドアウト検証」と呼びます。
パッケージやデータの準備
from sklearn.metrics import confusion_matrix import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline X_train, X_valid, y_train, y_valid = model_selection.train_test_split(X_train, y_train, test_size=0.25, random_state=0)
訓練と予測
clf = GradientBoostingClassifier(random_state=0)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_valid)
精度の検証
from sklearn.metrics import accuracy_score accuracy_score(y_valid, y_pred)
0.9642857142857143
conf_mat = confusion_matrix(y_valid, y_pred) index = list("012") columns = list("012") df = pd.DataFrame(conf_mat, index=index, columns=columns) fig = plt.figure(figsize = (7,7)) sns.heatmap(df, annot=True, square=True, fmt='.0f', cmap="Blues") plt.title('iris dataset') plt.xlabel('truth') plt.ylabel('prediction')

交差検証(Cross Validation、CV)を実行した場合
さて、ここで「Cross Validation」を実行すると、ホールドアウト検証の例よりも、更に汎用的に性能を確認できます。

Cross Validationでは、上図のように複数回に(図では3回)わたって異なるようにデータセットを分割し、それぞれでホールドアウト検証を実行します。その平均のスコアを確認することで、1回のホールドアウト検証で生じうる偏りに対する懸念を弱めることができます。
パッケージやデータの準備
from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score kf = KFold(n_splits=3, shuffle=True, random_state=0) iris_data = pd.DataFrame(data=iris.data, columns=iris.feature_names) iris_label = pd.Series(data=iris.target) X_train, X_test, y_train, y_test = model_selection.train_test_split(iris_data, iris_label, test_size=0.25, random_state=0)
訓練と予測と精度の検証
clf = GradientBoostingClassifier(random_state=0)
scores = cross_val_score(clf, X_train, y_train, cv=kf)
scores
array([ 0.97368421, 0.91891892, 0.97297297])
1回のみのホールドアウト検証のスコアより高いスコアが2件、低いスコアが1件出ています。このこと自体が、1回のホールドアウト検証でスコアを判断することの危うさを表しています。Cross Validationでは、全体の平均をスコアとします。
scores.mean()
0.95519203413940268
世界ランキング1位 bestfitting氏のコメント

世界ランキング1位のbestfitting氏も、Kaggleのインタビューでvalidationの重要性を強調するコメントを残しています。括弧内は私による日本語訳です。
What is your approach to solid cross-validation/final submission selection and LB fit?
(確かなCVを作るための手法とどのように最終的な提出ファイルを決めているかを教えてください)A good CV is half of success. I won’t go to the next step if I can’t find a good way to evaluate my model.
(良いCVが得られれば、成功の道半ばに到達したと言える。私は、モデルの良い評価方法が得られるまで、次のステップへ進まない)
To build a stable CV, you must have a good understanding of the data and the challenges faced. I’ll also check and make sure the validation set has similar distribution to the training set and test set and I’ll try to make sure my models improve both on my local CV and on the public LB.
(確かなCVを作るためには、データと解くべき問題を明確に理解しなければならない。そしてvalidationのデータセットがtrainのデータセットとtestのデータセットと同様の分布になっているか確かめ、local CVとpublic LBの両者を改善するようなモデルを作っていく)
In some time series competitions, I set aside data for a period of time as a validation set.
(時系列データを扱うコンペでは、一定期間をvalidationのデータセットとして確保する)
I often choose my final submissions in a conservative way, I always choose a weighted average ensemble of my safe models and select a relatively risky one (in my opinion, more parameters equate to more risks). But, I never chose a submission I can’t explain, even with high public LB scores.
(私は基本的に保守的な考え方で、最終的な提出ファイルの二つを決める。一つは「安全な」モデルの重み付きアンサンブルで、もう一つは比較的「危険な」モデルを選ぶ。パラメータが多いモデルの方が一般的に「危険」である。たとえpublic LBがどれほど良くても、私は決して自分で説明ができないモデルは選ばない)
おわりに
本記事では、「Cross Validationはなぜ重要なのか」を具体例とともに説明しました。
次回は、Twitterで頂いたリプの本題である「validationの切り方」についてまとめたいと思います。
本記事のソースコードはGitHubで公開しました。
github.com