validationの切り方いろいろ(sklearnの関数まとめ)【kaggle Advent Calendar 4日目】
本記事は、kaggle Advent Calendar 2018の4日目の記事です。
はじめに
本記事では、3日目の記事で重要性を説明したCross Validationについて、「良いCV」となるvalidationのデータセットはどのようなものか考えてみたいと思います。
この話題については、scikit-learnのドキュメンテーションが非常に充実しています。本記事でも、ソースコードを大いに流用しました。
Visualizing cross-validation behavior in scikit-learn — scikit-learn 0.21.3 documentation
重要な視点
「良いCV」は何かを考える上で重要なのは、前回の記事で引用したbestfitting氏も述べていたように、データと解くべき問題を明確に理解することです。
具体的には、例えば以下のようなポイントが大切になります。
- 分類問題か回帰問題か
- 分類問題の場合、各クラスの数に偏りはないか
- 順番に意味のあるデータか(時系列データであるか)
このようなデータや解くべき問題に応じて、適切な手法でvalidationのデータセットをtrainのデータセットから切り出す必要があります。
scikit-learnに用意されている関数
今回はscikit-learnのドキュメンテーションの例に沿って、次のような3クラス分類のデータセットを考えてみます。説明のため、クラス0が水色、クラス1が橙色、クラス2が茶色とします。
クラスとは別の概念として、データセット全体は均等な10グループに分割されています。グループはなかなかイメージが付きづらいかもしれませんが、例えば「同じユーザのデータを一つのグループにまとめておく」といった使い方が想定できます。同じユーザのデータがtrainのデータセットとvalidationのデータセットの両者に存在すると、不当に精度が高くなる恐れがあるためです。
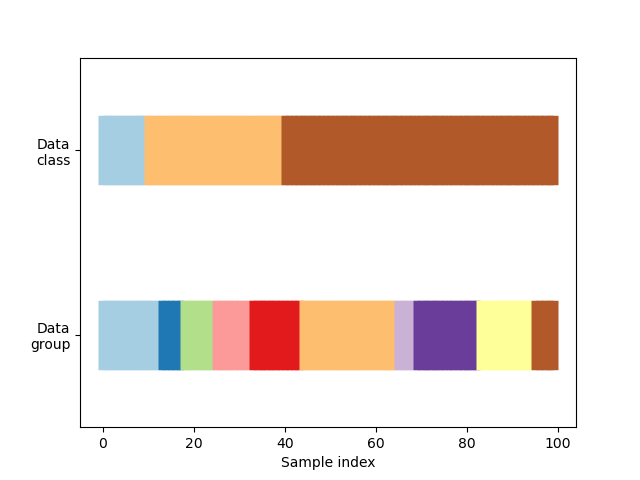
scikit-learnに用意されている関数を用いて、このデータセットをtrainのデータセットとvalidationのデータセットに切り分けてみましょう。
KFold
sklearn.model_selection.KFold — scikit-learn 0.21.3 documentation

上図のように、データセットを指定したn個に(デフォルトでは順序を変えることなく)分割します。赤がvalidationのデータセット、青がtrainのデータセットです。
個々の分割を見てみると、分割2と分割3では、全てのvalidationのデータセットがクラス2(茶色)になっています。一方で分割0のvalidationのデータセットにはクラス2(茶色)が全く含まれていません。全ての分割でクラスが偏った状況になっており、適切なスコアが得られないことが分かります。
StratifiedKFold
sklearn.model_selection.StratifiedKFold — scikit-learn 0.21.3 documentation

上図のように、データセット全体のクラスの偏りを保持しながら、データセットを分割できます。KFoldと比較して、このデータセットにおいては「良いCV」となっていると言えるでしょう。
GroupKFold
sklearn.model_selection.GroupKFold — scikit-learn 0.21.3 documentation
上図のように、同じグループが異なる分割パターンに出現しないようにデータセットを分割できます。GroupKFoldが必要な具体的事例は、iwiwiさんのスライドや動画が分かりやすいです。

ShuffleSplit
sklearn.model_selection.ShuffleSplit — scikit-learn 0.21.3 documentation

上図のように、ごちゃまぜで分割します。各分割でデータセットをシャッフルして考えているため、データの重複が許容されています。
GroupShuffleSplit
sklearn.model_selection.GroupShuffleSplit — scikit-learn 0.21.3 documentation

上図のように、グループ単位でランダムにvalidationのデータセットに割り当てるように分割します。GroupKFoldと比べると、例えば一番左のグループが一度もvalidationのデータセットとして使われていません。これは、ShuffleSplitと同様に各分割でデータセットをシャッフルして考えているため、データの重複(つまりは使われないデータの存在)が許容されるからです。
StratifiedShuffleSplit
sklearn.model_selection.StratifiedShuffleSplit — scikit-learn 0.21.3 documentation

上図のように、データセット全体のクラスの偏りを保持しながら、データセットを分割できます。GroupShuffleSplitとGroupKFoldの比較と同様、StratifiedShuffleSplitもStratifiedKFoldと比較すると、データの重複が許容されていると分かります。必ずしも全てのデータがvalidationのデータセットに一度使われるわけではありません。

回帰問題の場合
ここまで分類問題を例として扱ってきましたが、回帰問題の場合もこれらの分割方法が利用できます。回帰問題ではクラスという概念がありませんが、例えば目的変数を1変数でk-meansで適当に分類することで、擬似的にクラスを作成してStratifiedKFoldを用いることも可能です。
必ずしも「Trust CV」ではない
ここまでの議論では「trainのデータセットとtestのデータセットで各クラスの分布が似通っている」という前提に基づいて話を進めてきました。しかし時には、trainのデータセットとtestのデータセットで分布が異なる場合もあるかもしれません。
例えば極端な例ですが、trainのデータセットではクラス0:クラス1:クラス2 = 1:3:6 なのに、testのデータセットではクラス0:クラス1:クラス2 = 5:5:0 のような場合です。この場合には、どれほどtrainのデータと解くべき問題を明確に理解して「良いCV」、つまりはtrainのデータセットと分布が等しいvalidationデータセットを作成しても、意味がありません。
testのデータセットの分布はコンペ終了時まで分かりませんが、「良いCV」を作った自信があるにもかかわらずlocal CVとpublic LBのスコアに大きな乖離がある場合は、trainのデータセットとtestのデータセットで分布が異なることを仮定しても良いかもしれません。
このような状況では「Adversarial Validation」の利用も検討できます。以前に簡単にまとめた記事があるので、興味があればご参照ください。