「Pythonによるアクセスログ解析入門」の題目で「PyCon JP 2021」で発表しました
10月16日に「PyCon JP 2021」で発表しました。PyCon JP は日本最大級のPythonユーザが集まるイベントです。私はイベント自体が初参加で「Pythonによるアクセスログ解析入門」の題目で提出したプロポーザルが採択されました。
発表では、普段業務で扱っているWebサービスのアクセスログを題材に、PythonのPandasを用いたデータ解析の技法や数々の応用事例を紹介しました。Zoomでの発表時間30分も盛況で、Discordでの質問時間30分にも20名近くの方に残っていただき、さまざまな観点で質疑応答や議論をすることができました。オンライン発表ながら、多くの方々の反響を頂き、私自身もよい学びの機会となりました。
他の方の発表では、将棋棋士の谷合廣紀さんとPythonのコア開発者のブラントブーカーさんによるキーノートが共に大変面白く、これだけでも参加した価値があったと感じました。
私は両日ともオンラインでの参加でしたが、本イベントでは「リアル会場もありのハイブリット開催」という野心的な取り組みを実現していました。その中でも大きな問題なくイベントを遂行してくださった運営の方々にお礼申し上げます。
サイト
発表資料
サンプルコード

令和大相撲の暫定王者は白鵬(2020年4月時点)から誰かの手に渡ったのか?
大相撲で史上最多の45回の優勝を果たした横綱白鵬が29日、現役引退の日本相撲協会に届け出ました。30日の理事会で承認される見通しとのことです。
白鵬は2020年7月の名古屋場所で右膝の古傷が悪化して以降は休場続きで、2021年名古屋場所で復活の全勝優勝を果たしました。9月の秋場所場所は所属部屋の力士が新型コロナウイルスに感染した影響で全休となったため、連勝したまま土俵を去ることになっています。
遡ること2020年4月、令和大相撲の暫定王者を考える記事で、暫定王者になったのは白鵬でした。これは平成最後の「平成31年春場所」で優勝した白鵬を令和開始時の「王者」とし、その後の取り組みで「王者」に勝利した力士を次の「王者」としていく取り組みです。暫定王者はさまざまな力士を巡り巡って、最終的に白鵬の手に戻ってきていました。
本記事では、2020年5月場所以降の結果を追って、現在暫定王者の称号がどの力士の手に渡っているかを確認します。白鵬の休場開始のタイミングや最後の出場場所の対戦相手によっては、白鵬が暫定王者を背負ったまま引退している可能性もあるかもしれません。
令和2年夏場所
2020年5月に開催予定だった夏場所ですが、新型コロナウイルスの感染拡大などを受けて中止になりました。
白鵬(場所自体が中止のため変動なし)
令和2年名古屋場所
白鵬(1〜10日目)→大栄翔(11〜15日目)
2場所ぶりの開催となった名古屋場所で、白鵬は圧巻の10連勝スタート。10日目は横綱として1000回目の出場でもあり、全勝で並んでいた朝乃山が破れて単独首位に立ちました。しかし翌日、そこまで6勝4敗と決して好調とは言い難かった小結・大栄翔に立ち会いから体勢を崩されて敗北。白鵬は翌日も御嶽海に敗れ、13日目からは休場となりました。
大栄翔は白鵬に勝利した勢いそのまま、千秋楽まで連勝街道。11勝4敗で、殊勲賞を受賞しました。
令和2年秋場所
玉鷲(1日目)→正代(2〜3日目)→照ノ富士(4〜9日目)→隆の勝(10〜12日目)→翔猿(13日目)→貴景勝(14〜15日目)
暫定王者が連勝を続けていた先場所と打って変わり、何度も暫定王者が入れ替わる事態となりました。関脇になった大栄翔は初日に玉鷲に敗れ、玉鷲も2日目に正代に敗れます。この時点で前頭筆頭まで番付を戻していた照ノ富士が4〜9日目まで連勝するも、暫定王者は隆の勝・翔猿を経て、最終的には大関・貴景勝の手に渡りました。
令和2年九州場所
貴景勝(1〜8日目)→翔猿(9日目)→照ノ富士(10〜15日目)→貴景勝(優勝決定戦)
白鵬と鶴竜の2横綱が全休で、場所中に朝乃山・正代の2大関が休場した場所は、大関・貴景勝が奮起しました。無傷の8連勝で勝ち越すと、9日に翔猿に敗れたものの1敗のまま千秋楽を迎え、照ノ富士に本割で負けた後の決定戦を制して優勝を果たしました。
令和3年初場所
御嶽海(1日目)→宝富士(2日目)→高安(3〜4日目)→大栄翔(5〜8日目)→宝富士(9〜10日目)→明生(11日目)→大栄翔(12〜15日目)
先場所優勝した貴景勝ですが、この場所は4連敗から始まり最終的には2勝8敗5休と散々な結果に終わりました。両横綱も引き続き全休の中、5〜8日目と12〜15日目に暫定王者の座に君臨したのは前頭筆頭・大栄翔でした。大栄翔はこの場所、13勝2敗で初優勝を飾りました。
令和3年春場所
白鵬(1〜2日目)→阿武咲(3日目)→朝乃山(4〜6日目)→霧馬山(7日目)→正代(8日目)→大栄翔(9〜11日目)→若隆景(12〜13日目)→碧山(14〜15日目)
番付を小結に上げた大栄翔と初日に対戦したのは、昨年の名古屋場所以来の復活を遂げた横綱・白鵬。白鵬は大栄翔を破り翌日も勝利しましたが、3日目に突如の休場。不戦敗で阿武咲に暫定王者が移りました。その後も暫定王者の座は安定することなく次々と遷移し、最後は前頭12枚目の碧山の手中に収まり場所を終えました。
令和3年夏場所
碧山(1〜8日目休場、9日目勝利)→宝富士(10〜12日目)→正代(13日目)→貴景勝(14〜15日目)→照ノ富士(優勝決定戦)
碧山は怪我の影響で9日目からの出場。出場初日こそ勝利したものの、翌日には宝富士に敗れました。場所終盤に暫定王者の座を争ったのは貴景勝と、この場所に再び大関に復帰した照ノ富士。千秋楽結びの一番は貴景勝が照ノ富士を破り優勝決定戦に持ち込みましたが、照ノ富士が決定戦を制して2場所連続の優勝を決めました。
令和3年名古屋場所
照ノ富士(1〜14日目)→白鵬(15日目)
暫定王者が巡り巡った過去数場所とは打って変わり、暫定王者で綱取りにも臨んだ照ノ富士が連勝街道を猛進しました。そして、先場所の全休を経て復帰した白鵬も、同じく14連勝。全勝同士の千秋楽を制した白鵬が復活の優勝を遂げると同時に、再び暫定王者に返り咲きました。
令和3年秋場所
白鵬(全休)
冒頭で述べた通り、白鵬は所属部屋の力士が新型コロナウイルスに感染した影響で全休となりました。場所後には引退を発表したため、今後は暫定王者をかけた取り組みが発生しません。令和大相撲の暫定王者を背負ったまま、引退という運びとなります。
おわりに
本記事では、令和大相撲の暫定王者の推移とともに、各場所を振り返りました。白鵬が暫定王者の肩書きを持ったまま引退することになり、綱取りの照ノ富士と長らく相撲界を支えた白鵬の全勝対決が、令和最後の暫定王者をかけた取り組みだったことになります。少し出来すぎな物語かもしれませんが、暫定王者という観点で振り返る相撲史も面白いなと感じました。平成最後の場所で優勝し、そして最後も暫定王者となったまま土俵を去っていった白鵬関に、感謝の意を表明したいと思います。
技術書の翻訳体験記2021(『Kaggle Grandmasterに学ぶ 機械学習 実践アプローチ』)
翻訳を担当した書籍『Kaggle Grandmasterに学ぶ 機械学習 実践アプローチ』(マイナビ出版)*1が、明日8月24日に発売されます*2。 本書は世界各国で出版・公開された書籍 "Approaching (Almost) Any Machine Learning Problem" *3の翻訳書です。
私自身、翻訳を生業にしているわけではありません。 書籍を翻訳して商用出版するというのは、初めての経験でした。 翻訳依頼を引き受けるに当たり、先人が公開していた知見*4*5が参考になりました。 本書の刊行を機に、私も得られた知見を少しでも共有するべく、体験記をまとめて公開します。
本書の概要
本書の概要は、以前に公開した別記事にまとめています。 端的に言うと、機械学習にまつわる基礎的な内容について、豊富なコードともに学ぶ内容です。 著者は国際的なデータサイエンスコミュニティ「Kaggle」で史上初めて全カテゴリで最上位の称号(Grandmaster、GM)を獲得した方で、日本ではKaggleコミュニティを中心に「4GM本」とも呼ばれ話題を呼びました。
翻訳の依頼と動機
原著は2020年6月に自費出版され、しばらくした後にPDFがGitHub上で無料公開されました。
私は6月の発売と同時に購入し、平易な英語で豊富なコードと共に機械学習の広範な話題をまとめた内容に感銘を受けました。 交差検証や特徴量エンジニアリングなどモデル作成以前の重要な要素にも紙面が割かれ、コードの再現性やモデルのデプロイといった話題にも踏み込んでいます。 モデル作成では、表形式のデータセットだけでなく、画像認識や自然言語処理に関する内容が具体的な実装と共に示されている点も貴重です。 本書の文言の節々からは、性能のみを追求するだけではなく、実運用にも重きを置いた著者の姿勢が垣間見えました。
そんな中で、私が翻訳の依頼を受けたのは2021年3月中旬でした。 日本語への翻訳によって、少しでも多くの方に原著の魅力に触れていただく機会になればと思い受諾を決めました。
購入する前に一度無料版をのぞいてみてください。すべての人がこのcode-firstの本を気に入るとは限りません 😉
— abhishek (@abhi1thakur) July 2, 2021
ここから無料版を見つけることができます。https://t.co/dgquJtaGAT https://t.co/gNLMBHq1K1
訳者の紹介
訳者について簡単に紹介しておきます。 本書の話題である機械学習については、大学時代の研究や現職の業務を通じた経験があります*6。 Kaggleについても、CompetitionsとNotebooksでMasterの称号を持ち、チームでの優勝経験があります*7。 商用出版も、共著で『PythonではじめるKaggleスタートブック』(講談社)*8を出版した経験がありました。 英語については、大学時代の研究から始まり、現在も打ち合わせ・情報収集・論文執筆など日常の業務で利用する機会があります。
作業時期・量
3月中旬に依頼を受けた後に諸条件の調整があり、作業に取り掛かったのは4月頭でした。 この時点で、原著者や出版社と刊行の目標時期について擦り合わせしておくと良いでしょう。 今回の場合は、約300ページの書籍として比較的短い期限だと思いますが、5月末を自ら目標に掲げました。 本書の題材である機械学習は研究の進展が早く、時間を掛けてしまうと、せっかくの良書の価値が薄れてしまう懸念があったためです。
実際に作業時間を計測すると、10ページの翻訳に5〜10時間程度かかりました。 定期的にこなしていけば5月末は現実味のある期限だと分かり、目標に邁進していくことになります。
結果的には、4月中に約半分の150ページ、そしてゴールデンウィークで残りの半分の初稿が完成しました。 5月の残りの期間は「意図的に期間を置いて自分で推敲する」を時間の許す限り繰り返しました。 恐らく3サイクルくらいは回しています。 並行して原稿のレビュー依頼も出し、最終的に5月末に期限通り納入しました。
その後は出版社側の作業と、作成されたPDFの確認作業を経て、8月の出版に至ります。
利用したツール
原稿はGitHubで管理し、エディタにはVSCodeを利用しました。 普段の業務や以前の商用出版でも利用経験があり*9、使い慣れていたのが理由です。 今回は一人での翻訳作業なので必ずしも必要なかった気がしますが、心の安寧を担保するために使っていました。
翻訳を開始する前に、原著のテキストデータ(WordやTeXファイル)をもらっておくのも大事な点です。 PDFなどの形式から抽出することも可能ですが、余計な負荷は避けるのが鉄則です。
苦労した点と対応
まずは訳語の統一です。
機械学習の分野は国際的に発展しているため、手法などの英語名の訳し方には苦慮しました。
自分の知る限り日本で一般的に浸透している訳語を選択しましたが、どの訳語を採用したかは必要に応じてREADME.mdなどにメモしておきました。
推敲時には、VSCodeの検索機能を使い、表記ブレがないかを洗い出す作業も行いました。
英語の処理で難しかった思い出があるのは、意外と「or」かもしれません。 「A or B」のような表現があったとき、AとBが並列で記される単語なのか、もしくはBがAの言い換え表現なのかを判断するには、専門知識が必要でした。
英語の1文をそのまま日本語に訳すと過度に長くなる場合もありました。 こうした場合には、適切なタイミングで句読点や括弧などを入れて対応しました。
仕方のないことですが、原著の出版時からの時の流れに起因し、記載されている情報が現時点で異なっていることがあります。 また日本特有の事例として、補足が必要な場合もありました。 これらの要素については、出版社に確認の上で翻訳版独自の訳注を付けることに決めました。
合わせて、訳者によるまえがきも別途書き下ろしました。 こうした独自要素の追加が可能かについては、確認しておくと良いでしょう。
おわりに
本記事では、技術書の翻訳を通じて得られた知見を少しでも共有するべく、体験記をまとめました。 少しでも、後のどなたかの参考になれば幸いです。
*2:一部店舗では、既に店頭に並んでいるようです
Google Colab Pro+ 契約してみた
Google Colab の最上位プランとして「Pro+」が登場しました。Twitterの検索結果を見ると、日本時間の2021年8月12日午後辺りが初出のようです。
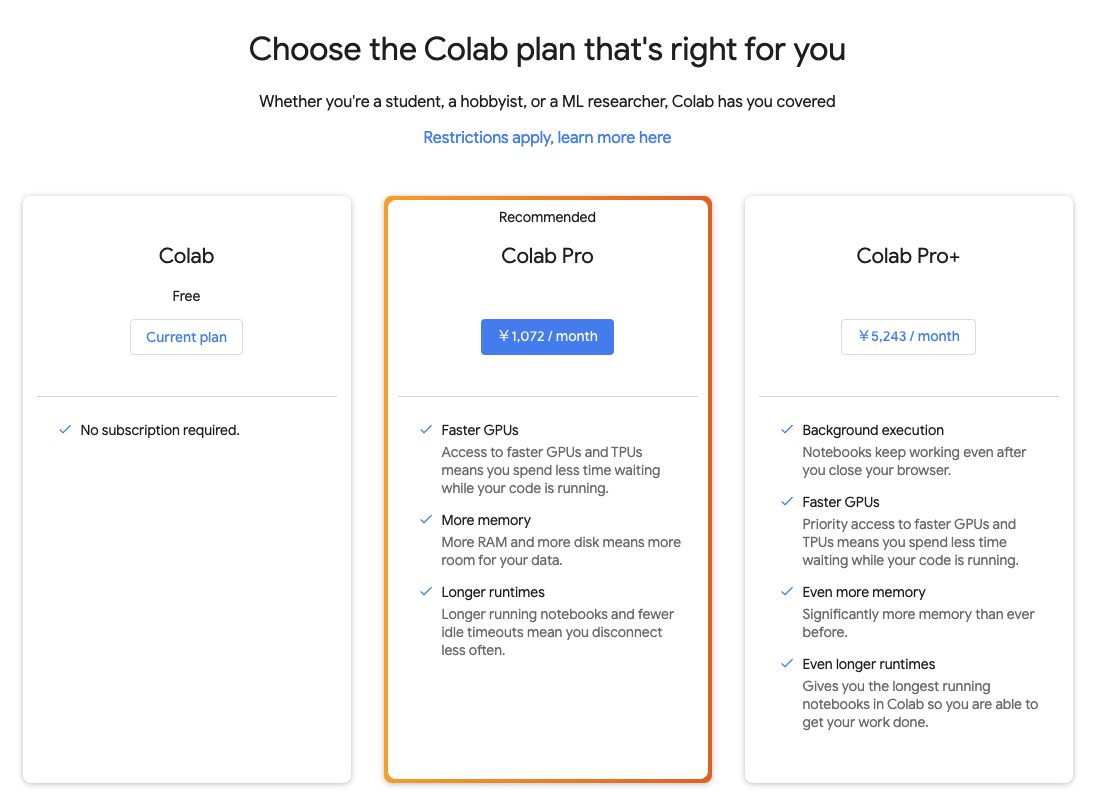
上記サイトの説明によると、既存の「Pro」プランに比べて、以下の利点があるそうです。
- Background execution
- ブラウザを閉じても実行を継続
- Faster GPUs
- より高速なGPUやTPUへの優先アクセス権
- Even more memory
- より大きなRAM
- Even longer runtimes
- より長い実行時間
FAQを見ると、既に日本でも利用可能とのことでした。
Where are Colab Pro and Pro+ available? For now, both Colab Pro and Pro+ are only available in the following countries: United States, Canada, Japan, Brazil, Germany, France, India, United Kingdom, and Thailand
利用できるRAMを次の表にまとめました。 ちなみにProプランでは、CPUとGPUのhigh-RAMモードで25.46GBが利用可能だったと記憶しています。
| RAM(GB) | CPU | GPU | TPU |
|---|---|---|---|
| standard | 13.6 | 13.6 | 13.6 |
| high-RAM | 54.8 | 54.8 | 37.8 |
TPUはv2でした。

Kaggle「CommonLit Readability Prize」コンペ25位の振り返りと上位解法まとめ
8月2日に終了したKaggle「CommonLit Readability Prize」コンペにチームで参加し、25位でした。 3682チーム参加で、17位までが金メダル圏内で、もう一歩という結果でした。

コンペ概要
英語の文章の「読みやすさ」の値を-3から3程度の範囲(大きいほど読みやすい)*1で予測する問題でした。 正解の値は、2つの文章の比較結果を利用する「Bradley–Terry model」*2で付けられていたそうです*3。 推論時は文章単体に対してスコアを予測する必要がありました。 データセットのサイズは小さく、学習用データセットが約3000で、評価用データセットが2000*4以下でした。
与えられたデータセットのカラムは、以下の通りです。 基本的には、文章の列のみを利用するチームが多かったです。
- id: インデックス番号
- url_legal: URL(学習用データセットのみ)、欠損あり
- license: ライセンス(学習用データセットのみ)、欠損あり
- excerpt: 文章
- target: 目的変数
- standard_error: 複数人の評価によって得られた分散(学習用データセットのみ)
値を予測する回帰問題で、評価指標はRMSE*5でした。 推論部分のコードを notebook に記述して提出する形式で、制限時間は3時間でした。
チームでの取り組み
4人チームで取り組んだ内容については、discussion*6に投稿しています。
簡単に概要を述べると、次の2種類の第1段階モデルの結果を、2種類の線形回帰モデルでstackingしました。
コンペで利用していたGitHubリポジトリを公開しました。 チームメイトのshigeriaさんも、日本語のブログ記事を書いています。
上位解法
discussionに公開された上位解法と簡単なメモを以下にまとめておきます。
全体共通の傾向
- roberta-largeなどの言語モデルを複数利用しアンサンブル
- dropoutを除外することで性能が向上したという報告が目立った
- 直近で日本では「回帰問題でニューラルネットワークを使う場合にdropoutは避けるべき」という記事が話題になっていた*8
hidden_dropout_probなども含めて消していた事例も
config.update({"output_hidden_states":True,
"hidden_dropout_prob": 0.0,
"layer_norm_eps": 1e-7})
1位
- 外部データを利用
- モデルはalbert-xxlarge, deberta-large, roberta-large, electra-largeで、ridgeでstacking
2位
- 19個のモデルの重み付き平均
- roberta-base -> svr, roberta-base -> ridge, oberta-base, roberta-large, muppet-roberta-large, bart-large, electra-large, funnel-large-base, deberta-large, deberta-v2-xlarge, mpnet-base, deberta-v2-xxlarge, funnel-large, gpt2-medium, albert-v2-xxlarge, electra-base, bert-base-uncased, t5-large, distilbart-cnn-12-6
- マイナスの重みも存在
- 定数倍の後処理でスコアが0.001 ~ 0.002上がった
- ※ 25位チームのモデルで検証したが、スコアは悪化した
3位
- foldを切りながら、外部データに擬似ラベルを付与
- deberta-largeで大幅にprivate lbが伸びた
4位
- 大量のモデルを作成し、線形回帰でstacking
- 2位寄りの解法
5位
- 学習用データセットは文章のテーマに沿って並んでいたので、シャッフルしないKFoldを意図的に使って、ジャンルの異なる記事への汎用性を確認した
6位
9位
- データ数が少ないので、交差検証の分割数を増やすと良いという仮説を立て、実験結果もその通りだった
- (K=5,10,15,25) を試し、最終的には25を利用
- deberta-largeが良い性能を示した
- 一部のモデルでは、クロスエントロピーを最適化するような問題に変換
12位
- 外部データを使ってpretrainし、コンペデータでfinetuning
- 13モデルを利用
13位
- roberta-large, xlnet-large, electra-large, deberta-large
- pseudo labeling
14位
- xlnet largeがシングルベスト
- pseudo label, multi-level stacking, custom loss
15位
16位
- roberta-large, deberta_large, electra_large
- pseudo labeling
中高生向けに喋った×2
先日、中高生向けに喋る機会が2度ありました。共に光栄なことに母校で話す機会でした。平易な内容で自分語りを極力減らし、できる限り学生にとって「汎化性能」のある有意義な内容にするのに苦心しました。幸い、質疑応答の時間が設けられた前者では10個以上の質問が寄せられ、一定の目的は達せられたのかなと感じています。自分自身にとっても、参加者との対話を通じて、内省し初心に帰る良い機会でした。
- 東海高校OBが語る!マスコミにおけるデータサイエンティストの仕事, 第39回サタデープログラム, June 26th, 2021.
- 高校生のためのオープンキャンパス 2021年度『東大卒業生に聞いてみようー18歳のハローワーク』, July 11th, 2021.
本日、母校でもある東海高校中学サタデープログラムで90分お話しします!いきなり部活の顧問だった先生と遭遇して懐かしい。社でのデータ活用の取り組みについて、魅力や難しさをお話しする予定です〜 https://t.co/4Cvget0TtP pic.twitter.com/ZEbsPwP8P4
— u++ (@upura0) June 26, 2021
本日、オープンキャンパス参加してました。「自分が高校生の時は、ここまで考えられてなかったな〜」と感じることが多くて、楽しい時間でした。 https://t.co/bQg55dvQRo
— u++ (@upura0) July 11, 2021
関連
「4GM本」の翻訳書『Kaggle Grandmasterに学ぶ 機械学習 実践アプローチ』が出版されます
マイナビ出版より8月に『Kaggle Grandmasterに学ぶ 機械学習 実践アプローチ』と題した書籍が出版されることになりました。 世界各国で出版・公開された書籍 "Approaching (Almost) Any Machine Learning Problem" の翻訳書です。 豊富なコード例と機械学習にまつわる基礎的な内容を取り上げています。

https://www.amazon.co.jp/dp/4839974985/
"Approaching (Almost) Any Machine Learning Problem"は、国際的なデータサイエンスコミュニティ「Kaggle」で史上初めて全カテゴリで最上位の称号を獲得した Abhishek Thakur さん による書籍です。 日本ではKaggleコミュニティを中心に「4GM本」とも呼ばれ、話題を呼びました。
交差検証や特徴量エンジニアリングなどモデル作成以前の重要な要素にも紙面が割かれ、コードの再現性やモデルのデプロイといった話題にも踏み込みます。 モデル作成では、表形式のデータセットだけでなく、画像認識や自然言語処理に関する内容が具体的なPython実装と共に示されます。
"KaggleのGrandmasterが書いた本"と聞くと高尚な話題が展開される印象を受ける方もいるかもしれませんが、本書の節々からは性能を追求するだけではなく実運用にも重きを置いた著者の姿勢が垣間見えます。 Kaggleコミュニティに限らず機械学習に興味を持つ多くの方に手に取っていただきたい一冊です。
原著のPDFは下記リンクで無料公開されています。日本語への翻訳によって、より多くの方に触れていただく機会になれば嬉しいです。
購入する前に一度無料版をのぞいてみてください。すべての人がこのcode-firstの本を気に入るとは限りません 😉
— abhishek (@abhi1thakur) July 2, 2021
ここから無料版を見つけることができます。https://t.co/dgquJtaGAT https://t.co/gNLMBHq1K1
翻訳では、原著のニュアンスを保持しつつ、日本語として自然になるような訳を心掛けました。訳者の知る限り日本で一般的に浸透している訳語を選択しましたが、一部用語については英語名をそのまま利用しています。原著の出版時からの更新を含む点や日本特有の話題は、翻訳版独自の訳注も付けました。
出版に向けて校正など一部作業が残っていますが、より一層完成度の高い書籍をお届けできるよう邁進します。