国際会議「ACM WSDM」のワークショップ「Booking.com Data Challenge」で6位に
国際会議「ACM WSDM」のワークショップとして開催されていた「Booking.com Data Challenge」*1で6位に入りました*2。Wantedly の hakubishin3 さんと Yuya Matsumura さん とのチームで、解法をまとめた論文は同ワークショップに採択・公開されました*3。同ワークショップは日本時間12日夜に開催され、主催者や上位チームがプレゼンテーションを実施します。

図は *2 より引用。
コンペ概要
世界最大規模の旅行代理店サイト「Booking.com」が主催で、たとえば「A->B->C」の旅程のユーザが、次にどこに行くか当てるという課題でした。このタスクが解けると、ユーザが旅行を予約した際に即座に「合わせて○○にも行ってみてはいかがですか?」といった推薦が実現できると説明されていました。
データセットとしては、以下の情報が与えられました。
- user_id: ユーザID
- check-in: ホテルのチェックイン日
- checkout: ホテルのチェックアウト日
- affiliate_id: ユーザのサイト訪問経路(直接か検索エンジンなど)
- device_class: デスクトップかモバイルか
- booker_country: ユーザの国(匿名)
- hotel_country: ホテルの国(匿名)
- city_id: 予測対象の都市(匿名)
- utrip_id: 旅程をまとめるID
Kaggle などのコンペと比べ、中間・最終にそれぞれ一度しかテスト用データセットへの予測値を提出できないのも特徴的でした。評価指標は「Precision@4」(4つの候補を挙げた上での正解率)でした。
チーム解法
最終的には4種類のLSTMモデルを作成し、予測値を重み付き平均しました。最初に主催者が公開している情報*4*5を基にベースラインとなるモデルを構築し、チームメイトと共に徐々に改善を重ねていきました。詳細は公開された論文*6やソースコード*7*8をご参照ください。

図は *6 より引用。
工夫した点をいくつか紹介しておきます。
まずは本来使えないはずの「予測対象の都市の滞在日数」という特徴量です。今回のコンペでは、実際に推薦を実施する時点では分からないはずの「予測対象のホテルのチェックアウト日」が与えられており、滞在した日数が計算できてしまいました。滞在日数は都市の特徴をよく表すことが想像でき、実際に性能の向上に貢献しました。

図は *6 より引用。
ニューラルネットワークの構造の工夫としては、都市と同時に国を当てるタスクも解く「マルチタスク・ラーニング」の枠組みも導入しました。

図は *6 より引用。
与えられたデータセットから、Word2Vecなどのグラフ関係の特徴量も作成しました。得られた都市のベクトル表現を2次元で可視化した結果を下図に示します。遠い目で見ると、世界地図に見えなくもない気もしました。

図は *6 より引用。
おわりに
本記事では、チーム参加して6位に入った「Booking.com Data Challenge」について紹介しました。旅行という身近で面白い題材に取り組みつつ、最終的には論文も書けて非常に有意義なコンペでした。一緒に取り組んだチームメイトに改めて感謝します。
*6:Shotaro Ishihara, Shuhei Goda and Yuya Matsumura: Weighted Averaging of Various LSTM Models for Next Destination Recommendation.
「GPT-3」周辺で調べたことをまとめる(2021年2月)
コンピュータサイエンス技術の一つに、自然言語処理(NLP)と呼ばれている領域があります。NLPは、コンピュータに人間の用いる言語(自然言語)を処理させる取り組み全般を指します。
ここ数年のNLPの傾向として、大規模テキストでの事前学習済みモデルの活用が挙げられます。代表的な例が、Googleが2018年10月に発表した「Bidirectional Encoder Representations from Transformers (BERT)」*1です。BERTは多数のNLPタスクで飛躍的な性能を示し、注目を集めました。BERTの登場後、大規模テキストを用いた巨大モデルを学習させていく流れが強まっています*2。
BERTの登場以前は、個別のタスクに対してモデルを訓練する取り組みが優勢でした。一方でBERTでは、事前に大量のテキストデータを用いて巨大なニューラルネットワークを学習させて汎用的なモデルを獲得し(事前学習)、その後に個別のタスクにモデルを適用していきます(ファインチューニング)。BERTの成果は、既に多くの領域で活用されています。Googleは2019年10月に自社の検索エンジンのアルゴリズムをBERTに基づく仕組みに刷新しました。同年12月には、日本語を含む72言語に拡張されました*3。
GPT-3の初期版の論文は、BERT登場前の2018年6月に公開されています*4。このモデルでは、BERTでも使われている「Transformer」と呼ばれる機構を12層用いて、言語モデルがファインチューニングを見据えた上での事前学習として有効であると示しました。言語モデルとは文の生成確率を定義したモデルで、近年はニューラルネットワークを用いて確率を推定するのが一般的です。本論文では「GPT」は「Generative Pre-Training」(生成的な事前学習)の略とされています。なお、GPTの研究に取り組んでいるのは、米電気自動車大手テスラCEOのイーロン・マスク氏らが共同設立したAI研究の非営利組織「OpenAI」です。
OpenAIは2019年2月、48層のTransformer機構を備えた「GPT-2」を発表しました*5。GPT-2は、ファインチューニングを実施せず、文章生成などのタスクに適用できる(ゼロショット)のが特徴です。
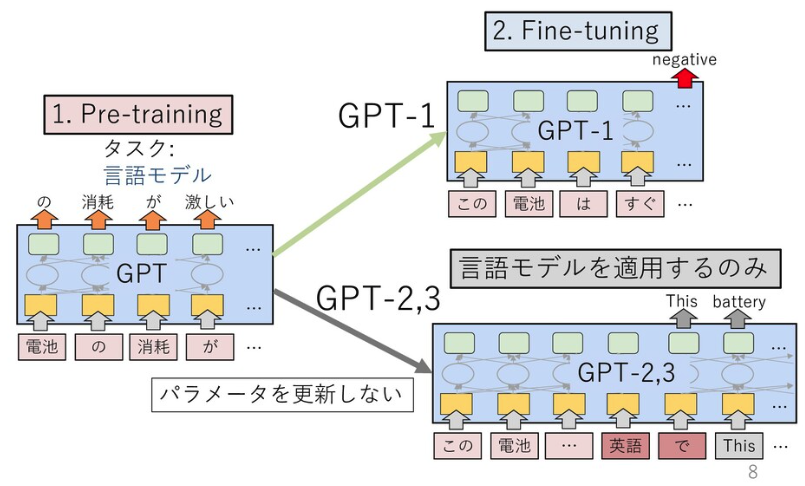 図は *6 より引用。
図は *6 より引用。
GPT-2は、人間も判別がつかないほどの高品質のフェイクニュースを生成できるとして、大きな話題を呼びました。発表時にはOpenAIが危険性を危惧し、論文公開を延期しモデルの公開も段階的に実施されました*7。
2020年5月に発表されたGPT-3は、GPT-2のパラメータ数を約116倍に拡張したモデルです*8。GPT-2ではゼロショットという枠組みを利用していましたが、GPT-3では少量の正答例を付与することで個別のタスクにモデルを適用します(Few-shot、フューショット)。具体的には、次のようにTask description(タスクの説明)、examples(回答例)、prompt(回答を促す文)を与えることで、回答を導出する枠組みです。ここで、GPT関連の論文で登場する「ゼロショット」「フューショット」という枠組みについては、その他一般で登場する同語と異なる概念になっている点には注意が必要です*9。
 図は [8] より引用。
図は [8] より引用。
OpenAIは2020年6月、GPT-3のAPIを公開しました。このAPIを駆使したデモを通じ、GPT-3の凄さが一挙に世間に広まりました*10*11。文章生成だけではなく、検索やLaTeXの数式・HTML・ソースコードの生成といったデモが公開されています。2020年8月には、米国の大学生がGPT-3で生成した偽のブログ記事で、ニュースサイト「Hacker News」のランキング1位を獲得したことも話題になりました*12。2020年10月には、MicrosoftがこのAPIの独占ライセンスを取得しています*13。
NLPの性能競争では、膨大なデータセットと巨大な計算資源が必要という潮流が強まっています。Transformer機構を用いた言語モデルの性能は、パラメータ数N・データセットサイズD・計算予算Cを変数とした冪乗則に従うという法則がOpenAIによって示されています*14。ウェブ上のデータセットは英語であることなどから、日本語に関する研究は英語圏に比べ遅れを取っていると言われています。日本でも一部の組織や開発者有志によって、日本語に関する言語モデルを学習・公開している事例はあります*15*16*17。2020年11月には、LINE株式会社がNAVERと共同で日本語に特化した超巨大言語モデルの開発についての取り組みを発表しました*18。
2021年1月、OpenAIは文章に忠実な画像を生成する「DALL·E」を発表しました*19。テキストと画像のペアのデータセットをGPT-3と同様の形式で学習したモデルです。GPT-3などで使われているTransformer機構は画像認識などNLP領域以外でも成果を発揮しつつあり、今後のさまざまな応用に期待が高まっています。DALL·Eと同時に発表された「CLIP」では、テキストを教師データとして利用した画像分類モデルが提案されました*20。CLIPは、GPT-2のゼロショットという枠組みに落とし込まれています。
*1:https://arxiv.org/abs/1810.04805
*2:https://speakerdeck.com/kyoun/survey-of-pretrained-language-models-f6319c84-a3bc-42ed-b7b9-05e2588b12c7
*3:https://www.blog.google/products/search/search-language-understanding-bert/
*4:https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
*5:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
*6:https://speakerdeck.com/tomohideshibata/gpt-3
*7:https://openai.com/blog/better-language-models/
*8:https://arxiv.org/abs/2005.14165
*9:https://zenn.dev/dhirooka/articles/34205e1b423a80
*10:https://deeplearning.hatenablog.com/entry/gpt3
*11:https://airtable.com/shrndwzEx01al2jHM/tblYMAiGeDLXe35jC
*12:https://www.technologyreview.com/2020/08/14/1006780/ai-gpt-3-fake-blog-reached-top-of-hacker-news/
*13:https://blogs.microsoft.com/blog/2020/09/22/microsoft-teams-up-with-openai-to-exclusively-license-gpt-3-language-model/
*14:https://deeplearning.hatenablog.com/entry/scaling_law
*15:https://github.com/tanreinama/gpt2-japanese
*16:https://cl.asahi.com/api_data/language_model.html
*17:https://tech.stockmark.co.jp/blog/gpt2_ja/
*18:https://linecorp.com/ja/pr/news/ja/2020/3508
*19:https://github.com/openai/DALL-E
*20:https://www.slideshare.net/DeepLearningJP2016/dllearning-transferable-visual-models-from-natural-language-supervision
東海高等学校・中学校「38thサタデープログラム」での発表資料
2月27日(土)開催の東海高等学校・中学校「38thサタデープログラム」で発表予定でしたが、残念ながら中止となりました。せっかくなので、発表予定だった資料を一部編集の上で公開します。ご興味ある方は、ぜひご覧ください。
2月に母校の「38thサタデープログラム」で講演予定です。中高生向けに、日頃の取り組みの楽しさや挑戦を噛み砕いて紹介できればと思っています。
— u++ (@upura0) January 12, 2021
全講座完全事前予約制で、その他の登壇者に河野太郎さん・松丸亮吾さん・平野綾さんら。https://t.co/tp6357rrMy
「Weekly Kaggle News」を横断検索できる仕組みを作った
概要
- 毎週金曜日に更新しているニューズレター「Weekly Kaggle News」を横断検索できる仕組みを作りました
- GitHubのレポジトリに全データを蓄積し、左上の検索ボックスからレポジトリ内を検索できます
- 最新号のデータをAPIで取得し、GitHub Actionsで自動更新するように設定しました

なぜ作った
基本的に自分用です。ニューズレターの発行を重ねるにつれ「この話題、昔どこかの号で取り上げたな」と感じる機会が増えてきました。そのような話題に言及する際、以前の書きぶりを確認する必要が生じます。ただし、現在使っているプラットフォーム「Revue」だと、過去の号を逐一開いて確認しなければなりませんでした。
要件
以上を踏まえて「過去の文字列を検索できること」が最低限の要件になります。また、可能であれば自動的に最新号までを検索対象に含めることが望ましいです。
どうやって作った
Revueが提供しているAPI と GitHub Actions のスケジュール機能 で実現できました。
データの取得に、RevueのAPIを使います。次のように、最新号のデータを取得するAPIを叩きました。データを取得した後は、適当にmdファイルに加工して保存します。
import argparse import requests if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--token') args = parser.parse_args() url = 'https://www.getrevue.co/api/v2/issues/latest' headers = {'Authorization': f'Token {args.token}'} req = requests.get(url, headers=headers)
https://github.com/upura/weekly-kaggle-news-archive/blob/master/get_latest_issue.py
あとはこのスクリプトを、定期実行するだけです。毎週土曜日に実行するよう設定しました。
on: schedule: - cron: '0 0 * * SAT'
https://github.com/upura/weekly-kaggle-news-archive/blob/master/.github/workflows/python-package.yml
おわりに
世の中に便利なものが多いおかげで、自分が欲しいものをサクッと作れるありがたい時代だなと感じます。高度な検索を作るならば、Elasticsearchなども検討して良いかもしれません。
2020年をザッと振り返る
年末恒例の振り返り記事です。あっという間に時間が経ちました。
コミュニティ活動
はてなブログは今年も100記事を達成できました。今年初めには、株式会社はてな東京オフィスを訪問する機会も頂きました。*1
印象深いのは、4月6日に公開された「言語処理100本ノック 2020」に取り組んだことです*2。今年は業務で自然言語処理の案件が増えたこともあり、ブログでも関連の話題が増えている印象があります。
「言語処理100本ノック 2020」のソースコード*3や、日本語の自然言語処理に関するスニペット集*4は、GitHubで公開しました。OSS貢献としては、日頃からお世話になっている「Optuna」*5に何度かPRを出せたのが記憶に残っています。
その他、今年は情報発信の場を広げることができました。昨年末に始めたニュースレターを休刊なく継続でき*6、4月にはYouTubeチャンネルも開設しました*7。
昨年末に大半の作業は終わっていましたが、初の著書が刊行されたのも今年でした*8。10月ごろからは、別の共著に着手しています。来年の早い時期に告知できるよう頑張ります。
コンペ
Kaggleのコンペでは、ソロの銀メダル・銅メダルが1枚ずつでした*9。NotebookとDiscussionでのMasterの称号が手の届く位置に来たので、来年あたりに達成できればと考えています。
その他のプラットフォームでは、以下で入賞することができました。
- Nishika, 財務・非財務情報を活用した株主価値予測 2nd (Solo), 2020.*10
- Basketball Behavior Challenge BBC2020 1st (Solo), 2020.*11
- Sansan × atmaCup #6 15th & LT大会 社会人枠最優秀LT賞 (Solo), 2020.*12
- CA × atmaCup 2nd 5th (Team), 2020.*13
英語
会社の研修制度を利用し、6〜12月にわたって英語研修を受けました。毎週1時間×3コマの英会話を受けるなど、英語を喋る機会が大きく増加しました。英作文やプレゼン練習なども含めて日常業務の合間にこなす日々はなかなかに大変でしたが、特にリスニング・スピーキングを中心に外部テストの成績からも成長が感じられた一年でした。
イベント
運営に関わっているイベント「Sports Analyst Meetup」*14を、4回開催できました。急遽のオンライン開催に切り替える中、多くの方々のご協力があってこそ実現したことだと感じています。
発表者の立場では、以下のイベント・番組に登壇する機会を頂きました。関係者の皆様に、改めてお礼申し上げます。
勉強会
- Kaggle Google Quest Q&A Labeling 反省会*15
- 第85回R勉強会@東京*16
- atmaCup#5 振り返り会*17
- Rist主催 Kaggle Workshop #1*18
- Google Cloud「Ask the Expert」*19
- AWS DEV DAY ONLINE JAPAN*20
- SciPy Japan 2020*21
- Sansan × atmaCup #6 LT大会*22
- データサイエンティスト協会シンポジウム*23
- Google Developers ML Summit*24
- CA x atmaCup 2nd 振り返り回*25
- Sports Analyst Meetup #9*26
Podcast
学会
仕事関連は世に出せる情報が必ずしも多くないのですが、以下2本については発表の機会を頂きました。来年も可能な範囲でこういった取り組みを継続していきたいです。
- Shotaro Ishihara, Norihiko Sawa (2020). Age Prediction of News Subscribers Using Machine Learning: Case Study of Hosting Worldwide Data Analysis Competition "Kaggle". Proceedings of Computation + Journalism Symposium 2020. Boston, MA, USA.
- 石原祥太郎 (2020). 新聞記事での共起回数を用いた関連企業の抽出. NLP若手の会 (YANS) 第15回シンポジウム, 2020年9月23日.
表彰
国際ニュースメディア協会が9月に発表した「30 Under 30 Awards」でアジア太平洋部門の最優秀賞を受賞しました*32。これからが大事という賞ですが、まずは過去の取り組みが評価されたことを嬉しく思います。
おわりに
今年はコロナ禍の到来と共に、社会の変化は突然やってくると改めて実感した一年でした。同時に、健康の大切さも身に沁みて感じています。来年も心身の安寧を保ちながら、可能な範囲で視野を広く持って精進していきたいところです。

「Weekly Kaggle News」1周年&購読者数1400人達成
「Kaggle Advent Calendar」 の20日目の記事です。
1年前に始めたニューズレター「Weekly Kaggle News」が1周年を迎えました。日本語で、Kaggleをはじめとするデータ分析コンペティションに関する話題を取り扱っています。週次で毎週金曜日に更新しており、12月18日の号で第53回の配信となりました。
購読者数は、ありがたいことに着実に増加しています。下図の赤は購読者数、青はユニークな開封数です。第53回を配信した数時間後に執筆している関係で、この回の開封数は少なめに出ていると予想されます。メール上で閲覧する以外に、ウェブ上で直接閲覧する手段もあります。最近のウェブ上でのページビューは300〜400程度で、合計すると1000人程度の方がご覧になっているようです。

第26回辺りで大きく伸びているのは、次の記事で取り上げられた影響です。地道に続けてきた20数回があったおかげだとは思いますが、影響力のあるウェブ記事の威力を改めて実感しました。
興味深いのは、第27回以降に購読者数は増加の一途をたどっている一方で、開封数にほとんど変動がない点です。この辺りは、ニューズレターという形態の一種の特性なのかもしれません。下図の黄色が示すニューズレター内のリンクのクリック率も、全ての回を通じて30%辺りを推移しています。

そもそものニューズレターを始めたきっかけは、創刊の記事でも少し触れた通り、近年のニュースメディアの動向でした。近年のSNSの急速な発展に伴う情報過多もあり、改めてニューズレターが持つ価値に注目が集まっています(参考: ニューヨーク・タイムズ「Journalists Are Leaving the Noisy Internet for Your Email Inbox」)。
Weekly Kaggle Newsは無料で公開を続けていますが、この活動を通じてニューズレターの特性や価値を自らの手で感じられているのは、私にとって大きな価値になっています。2020年9月には国際ニュースメディア協会から表彰されましたが、受賞理由の一つには個人での情報発信の活動が掲げられています。いつもご覧いただいている方々に、改めてお礼申し上げます。
最後に、過去にWeekly Kaggle News経由でクリックされたURLのランキングを算出してみました。単純なクリック回数なので、購読者数が増えている直近の回が有利な条件になっています。見落としていた記事があれば、ぜひご覧ください。全ての過去回も公開しています。
1位: 第34回、140クリック
2位: 第33回、131クリック
3位: 第36回、129クリック
4位: 第33回、123クリック
5位: 第37回、116クリック
6位: 第34回、114クリック
Kaggleで学んでハイスコアをたたき出す! Python機械学習&データ分析 | チームカルポ |本 | 通販 | Amazon
7位: 第26回、109クリック
8位: 第31回、105クリック
9位: 第30回、98クリック
書籍『Approaching (Almost) Any Machine Learning Problem』の日本版 Amazon へのリンク(※ 現在はリンク切れ)
10位: 第52回、96クリック
11位: 第40回、95クリック
11位: 第30回、95クリック
PDF『Deep Learning with PyTorch』の無料公開ページ(※ 現在はリンク切れ)
13位: 第51回、94クリック
14位: 第52回、93クリック
15位: 第51回、90クリック
www2.slideshare.net
15位: 第39回、90クリック
「Sports Analyst Meetup #9」をオンラインで開催しました #spoana
「Sports Analyst Meetup #9」*1を、12月13日に開催しました。7、8回目に引き続きのオンライン開催でした。
資料
togetter
発表内容
今回はロングトーク1本、LT6本という構成でした。
ロングトークでは、株式会社ユーフォリアのCEOとエンジニアの両名から、アスリートのコンディションやトレーニングに必要な情報を一括して記録・管理できるデータマネージメントツール『ONE TAP SPORTS』について講演していただきました。ツールとしての機能のみならず、サービスの背景にある思いが垣間見えた素晴らしい発表だと感じました。
LTで扱われた競技はバスケットボール・サッカー・野球と、今回は王道のスポーツが出揃いました。私自身も、以前にブログに書いた「Basketball Behavior Challenge 1st Place Solution」について発表しました。全ての資料がconnpassに挙がっているので、ぜひご覧ください。
- Basketball Behavior Challenge 1位解法(バスケ)
- 八村塁はどんな選手になり得るのか?(バスケ)
- 集団スポーツの軌道予測(2)(バスケ・サッカー)
- 海外のFootball Performance Analyst要件から考えてみた(サッカー)
- 慶大野球部のリーグ戦中にアナリストの僕が取り組んだこと(野球)
- 坂本勇人が通算3,000本安打を打つまで何年かかるかを機械学習でいい感じに出してみる(野球)
アーカイブ
オンライン開催の利点を活かして、発表者の許諾が得られた内容については、YouTubeにアーカイブを掲載していく予定です。
おわりに
今回も多くの方にご参加・ご発表いただき、誠にありがとうございました。多くの方に支えられ、2020年も4度に渡ってspoanaを開催できたことは、運営として嬉しい限りです。来年も、引き続きよろしくお願いいたします。